leetcode weekly contes 357 最近周赛状态越来越不稳定,感觉还是智商有限,很难突破。
6925. 故障键盘 你的笔记本键盘存在故障,每当你在上面输入字符 'i' 时,它会反转你所写的字符串。而输入其他字符则可以正常工作。
给你一个下标从 0 开始的字符串 s ,请你用故障键盘依次输入每个字符。
返回最终笔记本屏幕上输出的字符串。
示例 1:
输入:s = "string" 输出:"rtsng" 解释: 输入第 1 个字符后,屏幕上的文本是:"s" 。 输入第 2 个字符后,屏幕上的文本是:"st" 。 输入第 3 个字符后,屏幕上的文本是:"str" 。 因为第 4 个字符是 'i' ,屏幕上的文本被反转,变成 "rts" 。 输入第 5 个字符后,屏幕上的文本是:"rtsn" 。 输入第 6 个字符后,屏幕上的文本是: "rtsng" 。 因此,返回 "rtsng" 。
示例 2:
输入:s = "poiinter" 输出:"ponter" 解释: 输入第 1 个字符后,屏幕上的文本是:"p" 。 输入第 2 个字符后,屏幕上的文本是:"po" 。 因为第 3 个字符是 'i' ,屏幕上的文本被反转,变成 "op" 。 因为第 4 个字符是 'i' ,屏幕上的文本被反转,变成 "po" 。 输入第 5 个字符后,屏幕上的文本是:"pon" 。 输入第 6 个字符后,屏幕上的文本是:"pont" 。 输入第 7 个字符后,屏幕上的文本是:"ponte" 。 输入第 8 个字符后,屏幕上的文本是:"ponter" 。 因此,返回 "ponter" 。
提示:
1 <= s.length <= 100s 由小写英文字母组成s[0] != 'i'
地址 https://leetcode.cn/contest/weekly-contest-357/problems/faulty-keyboard/
题意 直接模拟
思路
直接模拟即可,遇到 $i$ 时将当前的字符串反转即可。
复杂度分析:
时间复杂度:$O(n^2)$, 其中 $n$ 表示字符的长度。
空间复杂度:$O(1)$。
代码 [sol1-C++] class Solution {public : string finalString (string s) { string res; for (auto c : s) { if (c == 'i' ) { reverse (res.begin (), res.end ()); } else { res.push_back (c); } } return res; } };
6953. 判断是否能拆分数组 给你一个长度为 n 的数组 nums 和一个整数 m 。请你判断能否执行一系列操作,将数组拆分成 n 个 非空 数组。
在每一步操作中,你可以选择一个 长度至少为 2 的现有数组(之前步骤的结果) 并将其拆分成 2 个子数组,而得到的 每个 子数组,至少 需要满足以下条件之一:
子数组的长度为 1 ,或者
子数组元素之和 大于或等于 m 。
如果你可以将给定数组拆分成 n 个满足要求的数组,返回 true ;否则,返回 false 。
注意: 子数组是数组中的一个连续非空元素序列。
示例 1:
输入:nums = [2, 2, 1], m = 4 输出:true 解释: 第 1 步,将数组 nums 拆分成 [2, 2] 和 [1] 。 第 2 步,将数组 [2, 2] 拆分成 [2] 和 [2] 。 因此,答案为 true 。
示例 2:
输入:nums = [2, 1, 3], m = 5 输出:false 解释: 存在两种不同的拆分方法: 第 1 种,将数组 nums 拆分成 [2, 1] 和 [3] 。 第 2 种,将数组 nums 拆分成 [2] 和 [1, 3] 。 然而,这两种方法都不满足题意。因此,答案为 false 。
示例 3:
输入:nums = [2, 3, 3, 2, 3], m = 6 输出:true 解释: 第 1 步,将数组 nums 拆分成 [2, 3, 3, 2] 和 [3] 。 第 2 步,将数组 [2, 3, 3, 2] 拆分成 [2, 3, 3] 和 [2] 。 第 3 步,将数组 [2, 3, 3] 拆分成 [2] 和 [3, 3] 。 第 4 步,将数组 [3, 3] 拆分成 [3] 和 [3] 。 因此,答案为 true 。
提示:
1 <= n == nums.length <= 1001 <= nums[i] <= 1001 <= m <= 200
地址 https://leetcode.cn/contest/weekly-contest-357/problems/check-if-it-is-possible-to-split-array/
题意 构造题
思路
正向构造感觉还是挺难的,此时设 $dp[l][r]$ 表示是否区间 $[l,r]$ 是否可以被分割,写一个比较麻烦的 $DFS$ 即可,比较蛋疼的是题目有两种特殊情况需要靠考虑:
子数组的长度只有 $1$;
子数组的和大于等于 $m$;
根据以上推论可以知道当数组长度为 $1$ 或者 $2$ 时则一定成立;
反过来思考,由于数组会被不断的切分,到最后一步切分一定是两个相邻的元素,此时如果数组中存在两个相邻的元素满足和大于等于 $m$, 则此时该数组一定可以被切分,每次去掉数组的两端的元素即可,一直不断的切即可完成所有元素的切割。
复杂度分析:
时间复杂度:$O(n)$,其中 $n$ 为数组的长度。
空间复杂度:$O(1)$。
代码 class Solution {public : bool canSplitArray (vector<int >& nums, int m) int n = nums.size (); if (n <= 2 ) { return true ; } vector<vector<int >> dp (n, vector <int >(n, -1 )); vector<int > sum (n + 1 ) ; for (int i = 0 ; i < n; i++) { sum[i + 1 ] = sum[i] + nums[i]; } function<bool (int , int )> dfs = [&](int l, int r) -> bool { if (r - l <= 1 ) { return true ; } if (dp[l][r] != -1 ) { return dp[l][r]; } bool res = false ; for (int i = l; i < r; i++) { if (i > l && sum[i + 1 ] - sum[l] < m) continue ; if (r - i > 1 && sum[r + 1 ] - sum[i + 1 ] < m) continue ; if (dfs (l, i) && dfs (i + 1 , r)) { res = true ; break ; } } dp[l][r] = res ? 1 : 0 ; return res; }; return dfs (0 , n - 1 ); } }; class Solution {public : bool canSplitArray (vector<int >& nums, int m) int n = nums.size (); if (n <= 2 ) return true ; for (int i = 1 ; i < n; i++) { if (nums[i - 1 ] + nums[i] >= m) { return true ; } } return false ; } };
6951. 找出最安全路径 给你一个下标从 0 开始、大小为 n x n 的二维矩阵 grid ,其中 (r, c) 表示:
如果 grid[r][c] = 1 ,则表示一个存在小偷的单元格
如果 grid[r][c] = 0 ,则表示一个空单元格
你最开始位于单元格 (0, 0) 。在一步移动中,你可以移动到矩阵中的任一相邻单元格,包括存在小偷的单元格。
矩阵中路径的 安全系数 定义为:从路径中任一单元格到矩阵中任一小偷所在单元格的 最小 曼哈顿距离。
返回所有通向单元格 (n - 1, n - 1) 的路径中的 最大安全系数 。
单元格 (r, c) 的某个 相邻 单元格,是指在矩阵中存在的 (r, c + 1)、(r, c - 1)、(r + 1, c) 和 (r - 1, c) 之一。
两个单元格 (a, b) 和 (x, y) 之间的 曼哈顿距离 等于 | a - x | + | b - y | ,其中 |val| 表示 val 的绝对值。
示例 1:
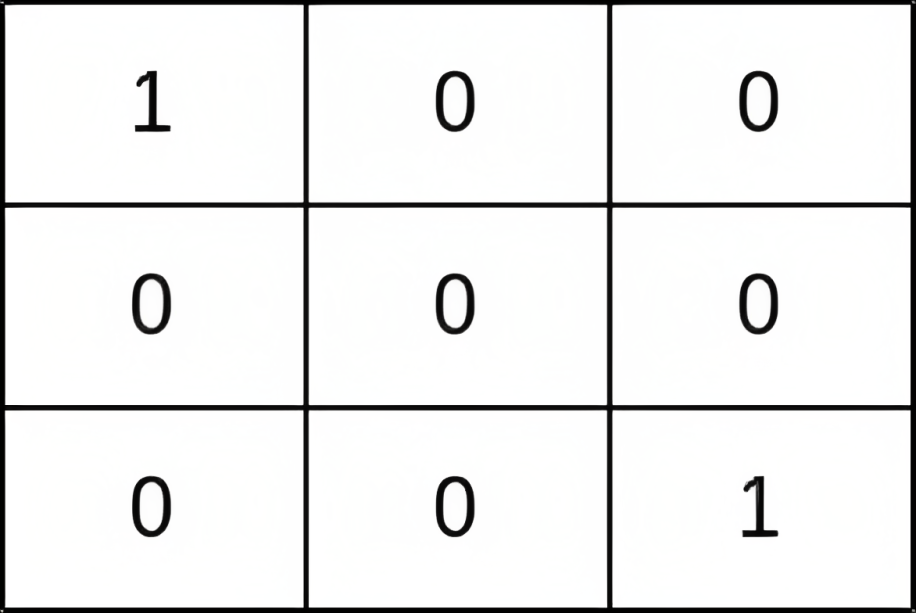
输入:grid = [[1,0,0],[0,0,0],[0,0,1]] 输出:0 解释:从 (0, 0) 到 (n - 1, n - 1) 的每条路径都经过存在小偷的单元格 (0, 0) 和 (n - 1, n - 1) 。
示例 2:
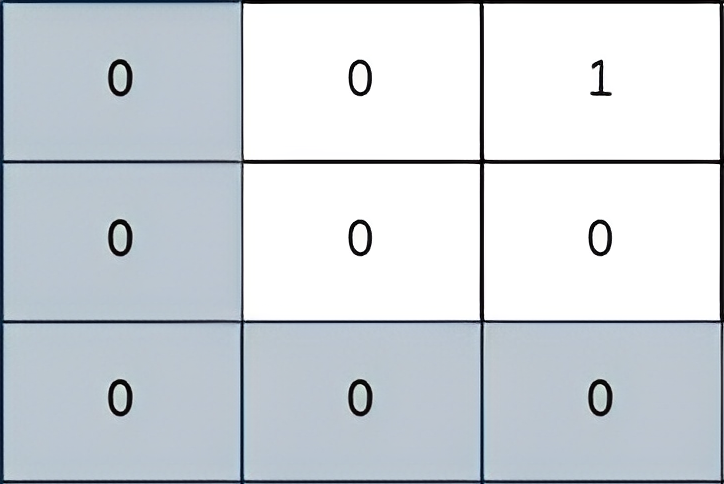
输入:grid = [[0,0,1],[0,0,0],[0,0,0]] 输出:2 解释: 上图所示路径的安全系数为 2: - 该路径上距离小偷所在单元格(0,2)最近的单元格是(0,0)。它们之间的曼哈顿距离为 | 0 - 0 | + | 0 - 2 | = 2 。 可以证明,不存在安全系数更高的其他路径。
示例 3:
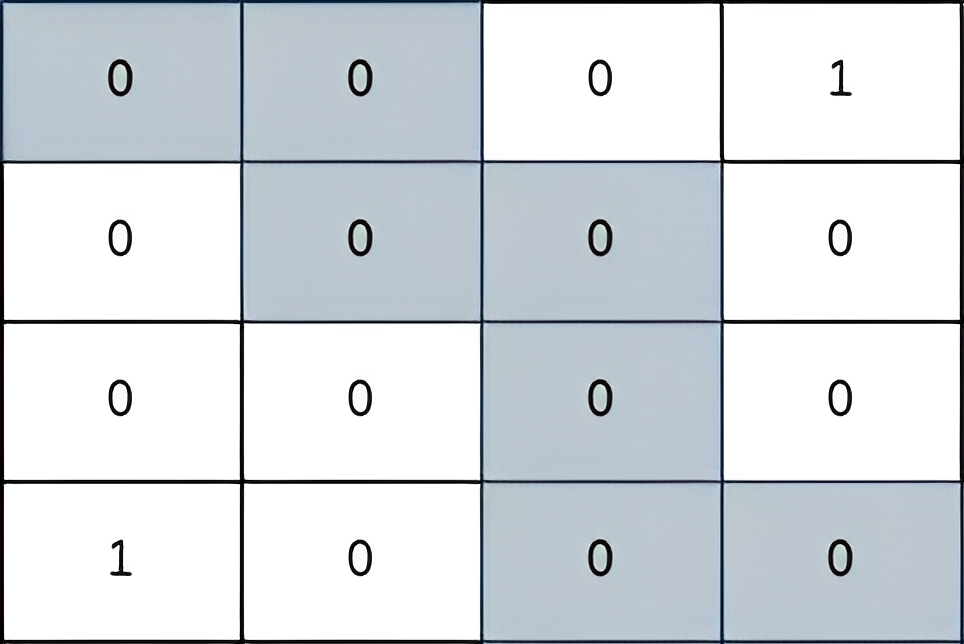
输入:grid = [[0,0,0,1],[0,0,0,0],[0,0,0,0],[1,0,0,0]] 输出:2 解释: 上图所示路径的安全系数为 2: - 该路径上距离小偷所在单元格(0,3)最近的单元格是(1,2)。它们之间的曼哈顿距离为 | 0 - 1 | + | 3 - 2 | = 2 。 - 该路径上距离小偷所在单元格(3,0)最近的单元格是(3,2)。它们之间的曼哈顿距离为 | 3 - 3 | + | 0 - 2 | = 2 。 可以证明,不存在安全系数更高的其他路径。
提示:
1 <= grid.length == n <= 400grid[i].length == ngrid[i][j] 为 0 或 1grid 至少存在一个小偷
地址 https://leetcode.cn/contest/weekly-contest-357/problems/find-the-safest-path-in-a-grid/
题意
二分查找
思路
二分查找的解法比较简单了,首先需要确定的每个格子的安全系数,即每个格子到所有小偷的最短距离,此时我们可以用多源最短路径即 $BFS$ 求出即可,这个关键步骤竟然弄错了,知道这一步后,后面的二分就每场简单了。
每次尝试当前的最大安全系统为 $maxdist$, 此时我们从起点 $(0,0)$ 开始遍历,只遍历那些安全系统大于等于 $maxdist$ 的格子即可,检测是否可以到达终点 $(n-1,n-1)$;
如果可以到达终点,则我们尝试将 $maxdist$ 再次进一步扩大;
如果可以无法终点,则我们尝试将 $maxdist$ 再次进一步缩小;
题目的关键在于如何求得每个格子到小偷的最短距离,这次需要用 $BFS$ 扩展求得即可;
复杂度分析:
时间复杂度:$O(n)$,其中 $n$ 表示给定数组的数目。
空间复杂度:$O(n)$,其中 $n$ 表示给定数组的数目。
代码 class Solution {public : using pii = pair<int , int >; constexpr static int dir[4 ][2 ] = {{-1 , 0 }, {1 , 0 }, {0 , 1 }, {0 , -1 }}; bool bfs (vector<vector<int >>& grid, int maxdist, vector<vector<int >>& dist) int n = grid.size (); queue<pii> qu; vector<vector<bool >> visit (n, vector <bool >(n, false )); qu.emplace (0 , 0 ); if (dist[0 ][0 ] < maxdist) return false ; visit[0 ][0 ] = true ; while (!qu.empty ()) { auto [cx, cy] = qu.front (); qu.pop (); if (cx == n - 1 && cy == n - 1 ) { return true ; } for (int i = 0 ; i < 4 ; i++) { int nx = cx + dir[i][0 ]; int ny = cy + dir[i][1 ]; if (nx < 0 || ny < 0 || nx >= n || ny >= n) continue ; if (visit[nx][ny]) continue ; if (dist[nx][ny] < maxdist) continue ; qu.emplace (nx, ny); visit[nx][ny] = true ; } } return false ; } int maximumSafenessFactor (vector<vector<int >>& grid) int n = grid.size (); vector<vector<int >> dist (n, vector <int >(n, -1 )); queue<pii> qu; for (int i = 0 ; i < n; i++) { for (int j = 0 ; j < n; j++) { if (grid[i][j]) { dist[i][j] = 0 ; qu.emplace (i, j); } } } while (!qu.empty ()) { auto [cx, cy] = qu.front (); qu.pop (); for (int i = 0 ; i < 4 ; i++) { int nx = cx + dir[i][0 ]; int ny = cy + dir[i][1 ]; if (nx < 0 || ny < 0 || nx >= n || ny >= n) continue ; if (dist[nx][ny] >= 0 ) continue ; qu.emplace (nx, ny); dist[nx][ny] = dist[cx][cy] + 1 ; } } int l = 0 , r = n * n; int res = 0 ; while (l <= r) { int mid = (l + r) >> 1 ; if (bfs (grid, mid, dist)) { l = mid + 1 ; res = mid; } else { r = mid - 1 ; } } return res; } }; class Solution {public : using pii = pair<int , int >; constexpr static int dir[4 ][2 ] = {{-1 , 0 }, {1 , 0 }, {0 , 1 }, {0 , -1 }}; int maximumSafenessFactor (vector<vector<int >>& grid) int n = grid.size (); vector<vector<int >> dist (n, vector <int >(n, -1 )); queue<pii> qu; for (int i = 0 ; i < n; i++) { for (int j = 0 ; j < n; j++) { if (grid[i][j]) { dist[i][j] = 0 ; qu.emplace (i, j); } } } while (!qu.empty ()) { auto [cx, cy] = qu.front (); qu.pop (); for (int i = 0 ; i < 4 ; i++) { int nx = cx + dir[i][0 ]; int ny = cy + dir[i][1 ]; if (nx < 0 || ny < 0 || nx >= n || ny >= n) continue ; if (dist[nx][ny] >= 0 ) continue ; qu.emplace (nx, ny); dist[nx][ny] = dist[cx][cy] + 1 ; } } priority_queue<tuple<int , int , int >> pq; vector<vector<bool >> visit (n, vector <bool >(n, false )); pq.emplace (dist[0 ][0 ], 0 , 0 ); int res = dist[0 ][0 ]; visit[0 ][0 ] = true ; while (!pq.empty ()) { auto [cost, cx, cy] = pq.top (); pq.pop (); res = min (res, cost); if (cx == n - 1 && cy == n - 1 ) { break ; } for (int i = 0 ; i < 4 ; i++) { int nx = cx + dir[i][0 ]; int ny = cy + dir[i][1 ]; if (nx < 0 || ny < 0 || nx >= n || ny >= n) continue ; if (visit[nx][ny] >= 0 ) continue ; visit[nx][ny] = true ; pq.emplace (dist[nx][ny], nx, ny); } } return res; } };
6932. 子序列最大优雅度 给你一个长度为 n 的二维整数数组 items 和一个整数 k 。
items[i] = [profiti, categoryi],其中 profiti 和 categoryi 分别表示第 i 个项目的利润和类别。
现定义 items 的 子序列 的 优雅度 可以用 total_profit + distinct_categories2 计算,其中 total_profit 是子序列中所有项目的利润总和,distinct_categories 是所选子序列所含的所有类别中不同类别的数量。
你的任务是从 items 所有长度为 k 的子序列中,找出 最大优雅度 。
用整数形式表示并返回 items 中所有长度恰好为 k 的子序列的最大优雅度。
注意: 数组的子序列是经由原数组删除一些元素(可能不删除)而产生的新数组,且删除不改变其余元素相对顺序。
示例 1:
输入:items = [[3,2],[5,1],[10,1]], k = 2 输出:17 解释: 在这个例子中,我们需要选出长度为 2 的子序列。 其中一种方案是 items[0] = [3,2] 和 items[2] = [10,1] 。 子序列的总利润为 3 + 10 = 13 ,子序列包含 2 种不同类别 [2,1] 。 因此,优雅度为 13 + 22 = 17 ,可以证明 17 是可以获得的最大优雅度。
示例 2:
输入:items = [[3,1],[3,1],[2,2],[5,3]], k = 3 输出:19 解释: 在这个例子中,我们需要选出长度为 3 的子序列。 其中一种方案是 items[0] = [3,1] ,items[2] = [2,2] 和 items[3] = [5,3] 。 子序列的总利润为 3 + 2 + 5 = 10 ,子序列包含 3 种不同类别 [1, 2, 3] 。 因此,优雅度为 10 + 32 = 19 ,可以证明 19 是可以获得的最大优雅度。
示例 3:
输入:items = [[1,1],[2,1],[3,1]], k = 3 输出:7 解释: 在这个例子中,我们需要选出长度为 3 的子序列。 我们需要选中所有项目。 子序列的总利润为 1 + 2 + 3 = 6,子序列包含 1 种不同类别 [1] 。 因此,最大优雅度为 6 + 12 = 7 。
提示:
1 <= items.length == n <= 105items[i].length == 2items[i][0] == profitiitems[i][1] == categoryi1 <= profiti <= 1091 <= categoryi <= n1 <= k <= n
地址 https://leetcode.cn/contest/weekly-contest-357/problems/maximum-elegance-of-a-k-length-subsequence/
题意
贪心
思路
假设选择了 $k$ 个元素,则此时的优雅度等于 $k$ 个元素的和再加上当前元素的种类数,因此我们贪心的选择 $k$ 个最大的元素:
此时如果当前的种类为 $x$, 则此时的优雅度为 $sum(A[0\cdots k-1]) + x^2$;
此时遍历下一个待选的元素 $A[k]$,此时可以分为以下几种情形讨论:
如果当前 $A[k]$ 的种类已经在选择的数组中出现过,则此时不需要选择 $A[K]$, 因为已经选择 $A[k]$ 的种类中已经包含了最大值;
如果当前 $A[k]$ 的种类已经在选择的数组中均未出现过,此时由于 $distinct_categories$ 可能变大,则此时需要在 $A[0,\cdots K]$ 中选择一个元素进行替换:
如果被替换的元素也只出现过一次,则此时 $distinct_categories$ 不会变化,因此我们不会替换掉只出现过一次的元素;
如果被替换的元素也只出现过多次,我们应该尽量选择重复且最小的元素进行替换。
另一种贪心的思路见 : 贪心 , 思路比较巧妙。分为几种情况讨论,首先设数组中的最优解中的种类数为 $m$ , 数组中总的种类数为 $t$;
$m = k$ 时: 在这种情况下,由于不同的种类均只含有一个元素,此时我们直接选择 $m$ 个类中最大元素即可;
枚举当前的最小种类数,当前然后依次将最大的 profit 的元素加入到待选序列中,我们可以知道当前待选的种类一定是大于等于 $i$ 的,此时依次枚举最大的 profit, 假设当前待选的种类时 $i$ 种时,此时我们一定选择的是最大的 $profit$;
复杂度分析:
时间复杂度:$O(n^2)$,其中 $n$ 表示数组的长度。
空间复杂度:$O(n^2)$,其中 $n$ 表示数组的长度。
代码 class Solution {public : long long findMaximumElegance (vector<vector<int >>& items, int k) int n = items.size (); sort (items.begin (), items.end (), [&](vector<int > &a, vector<int > &b) { return a[0 ] > b[0 ]; }); long long total_profit = 0 ; unordered_set<int > cnt; stack<int > duplicate; long long res = 0 ; for (int i = 0 ; i < n; i++) { int profit = items[i][0 ]; int category = items[i][1 ]; if (i < k) { total_profit += profit; if (cnt.count (category)) { duplicate.emplace (profit); } cnt.emplace (category); } else if (!cnt.count (category) && !duplicate.empty ()) { total_profit += profit - duplicate.top (); duplicate.pop (); cnt.emplace (category); } long long total = total_profit + cnt.size () * cnt.size (); res = max (res, total); } return res; } }; class Solution {public : long long findMaximumElegance (vector<vector<int >>& items, int k) int n = items.size (); vector<pair<int , int >> arr; for (int i = 0 ; i < n; i++) { arr.emplace_back (items[i][1 ], items[i][0 ]); } sort (arr.begin (), arr.end (), [&](pair<int , int > &a, pair<int , int > &b) { if (a.first == b.first) { return a.second > b.second; } return a.first < b.first; }); vector<int > b, c; for (int i = 0 ; i < n; i++) { auto [x, y] = arr[i]; if (i == 0 || arr[i - 1 ].first != x) { b.emplace_back (y); } else { c.emplace_back (y); } } sort (b.begin (), b.end (), [&](int x, int y) { return x > y; }); sort (c.begin (), c.end (), [&](int x, int y) { return x > y; }); for (int i = 0 ; i < n; i++) { b.emplace_back (INT_MIN); c.emplace_back (INT_MIN); } long long ans = 0 ; long long sum = accumulate (c.begin (), c.begin () + k, 0LL ); for (int i = 1 ; i <= k; i++) { sum = sum + b[i - 1 ] - c[k - i]; ans = max (ans, (long long ) i * i + sum); } return ans; } };
欢迎关注和打赏,感谢支持!