leetcode weekly contes 355
本周题目竟然时近期最难的题目了,虽然难,但是感觉比较有意思的题目了。$T4$ 确实比较有意思的思考题目了,关键的一步转化没有想清楚,太失败了。
2788. 按分隔符拆分字符串
给你一个字符串数组 words 和一个字符 separator ,请你按 separator 拆分 words 中的每个字符串。
返回一个由拆分后的新字符串组成的字符串数组,不包括空字符串 。
注意
separator用于决定拆分发生的位置,但它不包含在结果字符串中。- 拆分可能形成两个以上的字符串。
- 结果字符串必须保持初始相同的先后顺序。
示例 1:
输入:words = ["one.two.three","four.five","six"], separator = "." |
示例 2:
输入:words = ["$easy$","$problem$"], separator = "$" |
示例 3:
输入:words = ["|||"], separator = "|" |
提示:
1 <= words.length <= 1001 <= words[i].length <= 20words[i]中的字符要么是小写英文字母,要么就是字符串".,|$#@"中的字符(不包括引号)separator是字符串".,|$#@"中的某个字符(不包括引号)
地址
https://leetcode.cn/contest/weekly-contest-355/problems/split-strings-by-separator/
题意
直接模拟
思路
- 本质是手撕 $split$ 函数即可,没啥太大的难度,还是非常简单题目。
- 复杂度分析:
- 时间复杂度:$O(nm)$。其中 $n$ 表示字符串数组的长度, $m$ 表示字符串的平均长度。
- 空间复杂度:$O(m)$。
代码
class Solution { |
2789. 合并后数组中的最大元素
给你一个下标从 0 开始、由正整数组成的数组 nums 。
你可以在数组上执行下述操作 任意 次:
- 选中一个同时满足
0 <= i < nums.length - 1和nums[i] <= nums[i + 1]的整数i。将元素nums[i + 1]替换为nums[i] + nums[i + 1],并从数组中删除元素nums[i]。
返回你可以从最终数组中获得的 最大 元素的值。
示例 1:
输入:nums = [2,3,7,9,3] |
示例 2:
输入:nums = [5,3,3] |
提示:
1 <= nums.length <= 1051 <= nums[i] <= 106
地址
题意
贪心
思路
题目给出的关键在于只要满足 $nums[i + 1] \ge nums[i]$,此时两个元素即可合并,为了是合并的数足够的大,因此我们应当保证 $nums[i+1]$ 这个元素尽可能的大,因此我们从后往前合并即可,优先保证后面合并后的元素尽可能的大就可以往前合并更多的元素。为了方便我们可以用栈来实现,每次当前元素与栈顶元素进行合并。
复杂度分析:
- 时间复杂度:$O(n)$,其中 $n$ 为数组的长度。
- 空间复杂度:$O(n)$,其中 $n$ 为数组的长度。
代码
class Solution { |
2790. 长度递增组的最大数目
给你一个下标从 0 开始、长度为 n 的数组 usageLimits 。
你的任务是使用从 0 到 n - 1 的数字创建若干组,并确保每个数字 i 在 所有组 中使用的次数总共不超过 usageLimits[i] 次。此外,还必须满足以下条件:
- 每个组必须由 不同 的数字组成,也就是说,单个组内不能存在重复的数字。
- 每个组(除了第一个)的长度必须 严格大于 前一个组。
在满足所有条件的情况下,以整数形式返回可以创建的最大组数。
示例 1:
输入:usageLimits = [1,2,5] |
示例 2:
输入:usageLimits = [2,1,2] |
示例 3:
输入:usageLimits = [1,1] |
提示:
1 <= usageLimits.length <= 1051 <= usageLimits[i] <= 109
地址
题意
数学
思路
- 本质是个数学解法,如果需要满足第 $n + 1$ 列,此时需要满足两个条件:
- 当前总数需要满足大于等于 $\frac{(n + 1) \times (n + 2)}{2}$;
- 当前至少有 $n + 1$ 个不同的数;
- 满足以上条件才能使得一定满足当前的要求;
- 可以参考力扣美国站的解法:题解
- 复杂度分析:
- 时间复杂度:$O(n)$,其中 $n$ 表示数组的长度。
- 空间复杂度:$O(n)$,其中 $n$ 表示数组的长度。
代码
class Solution { |
2791. 树中可以形成回文的路径数
给你一棵 树(即,一个连通、无向且无环的图),根 节点为 0 ,由编号从 0 到 n - 1 的 n 个节点组成。这棵树用一个长度为 n 、下标从 0 开始的数组 parent 表示,其中 parent[i] 为节点 i 的父节点,由于节点 0 为根节点,所以 parent[0] == -1 。
另给你一个长度为 n 的字符串 s ,其中 s[i] 是分配给 i 和 parent[i] 之间的边的字符。s[0] 可以忽略。
找出满足 u < v ,且从 u 到 v 的路径上分配的字符可以 重新排列 形成 回文 的所有节点对 (u, v) ,并返回节点对的数目。
如果一个字符串正着读和反着读都相同,那么这个字符串就是一个 回文 。
示例 1:
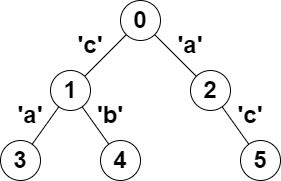
输入:parent = [-1,0,0,1,1,2], s = "acaabc" |
示例 2:
输入:parent = [-1,0,0,0,0], s = "aaaaa" |
提示:
n == parent.length == s.length1 <= n <= 105- 对于所有
i >= 1,0 <= parent[i] <= n - 1均成立 parent[0] == -1parent表示一棵有效的树s仅由小写英文字母组成
地址
题意
状态压缩 + 构造题目
思路
题目本质需要思考什么样的字符串数目可以构成回文字符串:
- 字符串中所有的小写字母均出现偶数次;
- 字符串中仅有一个字母出现奇数次,其余出现偶数次;
根据以上分析我们可以用 $26$ 位掩码来表示当前路劲中的字符的奇偶状态,如果第 $i$ 位为奇数则表示第 $i$ 个字母的次数为奇数,如果第 $i$ 位为偶数则表示第 $i$ 个字符的次数为偶数,对于任意的 $(u,v)$ ,我们可以知道他们之间的路径一定为 $u \rarr lca(u,v) \rarr v$, $mask(u,lca(u,v))$ 表示 $u$ 到 $lca(u,v)$ 的字符统计统计状态,$mask(lca(u,v), v)$ 表示 $lca(u,v)$ 到 $v$ 的字符统计状态,则此时可以知道:
- 如果 $mask(u,lca(u,v)) = mask(lca(u,v), v) $ 时,此时 $u \rarr v$ 路径上的所有字母均为偶数,一定可以构造出回文字符串;
- 如果 $mask(u,lca(u,v)) \oplus mask(lca(u,v), v) = 2^j$ 时,即二者仅有一个字母的奇偶性不同,则此时 $u \rarr v$ 路径上的所有字母数目有一个为奇数,其余字母数目均为偶数,此时也一定可以构造出回文字符串;
关键分析,还有一步需要如何转化,即 $mask(u,lca(u,v)) \oplus mask(lca(u,v), v) = mask(u,root) \oplus mask(root, v)$,即将掩码装换为从根节点到节点 $u,v$ 的状态转化,这一步很关键,因为直接求 $lca(u,v)$ 的话会比较麻烦,如果有 $n$ 个节点,则此时有 $n^2$ 对不同的节点对,此时直接求的话会比较麻烦,题目的关键在于这一步转换。如果知道上述装换以后,题目则变得非常简单了,根据以上思路转换后,直接利用 $DFS$ 和哈希表很快可以计算出结果来。
复杂度分析:
- 时间复杂度:$O(n|\Sigma|)$,其中 $n$ 为节点的数目。
- 空间复杂度:$O(n)$,其中 $n$ 表示给定的元素。
代码
class Solution { |
欢迎关注和打赏,感谢支持!
- 关注我的博客: http://whistle-wind.com/
- 关注我的知乎:https://www.zhihu.com/people/da-hua-niu
- 关注我的微信公众号: 公务程序猿

扫描二维码,分享此文章