leetcode contest 385
难得 AK 的题目,最近比较好的成绩,也可能全部都是字符串匹配的问题。
100212. 统计前后缀下标对 I
给你一个下标从 0 开始的字符串数组 words 。
定义一个 布尔 函数 isPrefixAndSuffix ,它接受两个字符串参数 str1 和 str2 :
- 当
str1同时是str2的前缀(prefix)和后缀(suffix)时,isPrefixAndSuffix(str1, str2)返回true,否则返回false。
例如,isPrefixAndSuffix("aba", "ababa") 返回 true,因为 "aba" 既是 "ababa" 的前缀,也是 "ababa" 的后缀,但是 isPrefixAndSuffix("abc", "abcd") 返回 false。
以整数形式,返回满足 i < j 且 isPrefixAndSuffix(words[i], words[j]) 为 true 的下标对 (i, j) 的 数量 。
示例 1:
输入:words = ["a","aba","ababa","aa"] |
示例 2:
输入:words = ["pa","papa","ma","mama"] |
示例 3:
输入:words = ["abab","ab"] |
提示:
1 <= words.length <= 501 <= words[i].length <= 10words[i]仅由小写英文字母组成。
地址
https://leetcode.cn/contest/weekly-contest-385/problems/count-prefix-and-suffix-pairs-i/
题意
直接模拟即可
思路
- 直接模拟即可,利用
python的切片可以直接实现。 - 复杂度分析:
- 时间复杂度:$O(n)$,其中 $n$ 表示给定数组的长度。
- 空间复杂度:$O(1)$。
代码
class Solution: |
100229. 最长公共前缀的长度
给你两个 正整数 数组 arr1 和 arr2 。
正整数的 前缀 是其 最左边 的一位或多位数字组成的整数。例如,123 是整数 12345 的前缀,而 234 不是 。
设若整数 c 是整数 a 和 b 的 公共前缀 ,那么 c 需要同时是 a 和 b 的前缀。例如,5655359 和 56554 有公共前缀 565 ,而 1223 和 43456 没有 公共前缀。
你需要找出属于 arr1 的整数 x 和属于 arr2 的整数 y 组成的所有数对 (x, y) 之中最长的公共前缀的长度。
返回所有数对之中最长公共前缀的长度。如果它们之间不存在公共前缀,则返回 0 。
示例 1:
输入:arr1 = [1,10,100], arr2 = [1000] |
示例 2:
输入:arr1 = [1,2,3], arr2 = [4,4,4] |
提示:
1 <= arr1.length, arr2.length <= 5 * 1041 <= arr1[i], arr2[i] <= 108
地址
题意
字典树,哈希表
思路
- 字典树的解法就比较简单了,每次添加新的字符串时搜索所有的字典树中的最长公共前缀即可。还可以用哈希算法,由于每个字符串的长度为 $m$,因此最多有 $mn$ 个不同的前缀,我们直接构造 $mn$ 个前缀即可。然后检测是否存在最长的前缀即可。
- 复杂度分析:
- 时间复杂度:$O(n \log U)$, $n$ 表示给定字符串 $s$ 的长度;
- 空间复杂度:$O(n)$;
代码
class TrieNode: |
100217. 出现频率最高的素数
给你一个大小为 m x n 、下标从 0 开始的二维矩阵 mat 。在每个单元格,你可以按以下方式生成数字:
- 最多有
8条路径可以选择:东,东南,南,西南,西,西北,北,东北。 - 选择其中一条路径,沿着这个方向移动,并且将路径上的数字添加到正在形成的数字后面。
- 注意,每一步都会生成数字,例如,如果路径上的数字是
1, 9, 1,那么在这个方向上会生成三个数字:1, 19, 191。
返回在遍历矩阵所创建的所有数字中,出现频率最高的、大于 10的素数;如果不存在这样的素数,则返回 -1 。如果存在多个出现频率最高的素数,那么返回其中最大的那个。
注意:移动过程中不允许改变方向。
示例 1:
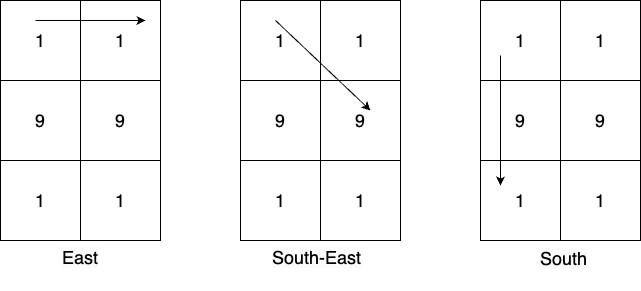
输入:mat = [[1,1],[9,9],[1,1]] |
示例 2:
输入:mat = [[7]] |
示例 3:
输入:mat = [[9,7,8],[4,6,5],[2,8,6]] |
提示:
m == mat.lengthn == mat[i].length1 <= m, n <= 61 <= mat[i][j] <= 9
地址
https://leetcode.cn/contest/weekly-contest-385/problems/most-frequent-prime/
题意
模拟
思路
- 该题目暴力模拟 $8$ 个方向,直到出现相关符合题目要求的素数即可,直接暴力模拟即可
- 复杂度分析:
- 时间复杂度:$O(nm\times(m+m) + mn\times sqrt(U))$,其中 $m,n$ 分别表示矩阵中的行数与列数。
- 空间复杂度:$O(|\Sigma|)$, $|\Sigma|$ 表示字符集的大小。
代码
def check(x): |
100208. 统计前后缀下标对 II
给你一个下标从 0 开始的字符串数组 words 。
定义一个 布尔 函数 isPrefixAndSuffix ,它接受两个字符串参数 str1 和 str2 :
- 当
str1同时是str2的前缀(prefix)和后缀(suffix)时,isPrefixAndSuffix(str1, str2)返回true,否则返回false。
例如,isPrefixAndSuffix("aba", "ababa") 返回 true,因为 "aba" 既是 "ababa" 的前缀,也是 "ababa" 的后缀,但是 isPrefixAndSuffix("abc", "abcd") 返回 false。
以整数形式,返回满足 i < j 且 isPrefixAndSuffix(words[i], words[j]) 为 true 的下标对 (i, j) 的 数量 。
示例 1:
输入:words = ["a","aba","ababa","aa"] |
示例 2:
输入:words = ["pa","papa","ma","mama"] |
示例 3:
输入:words = ["abab","ab"] |
提示:
1 <= words.length <= 1051 <= words[i].length <= 105words[i]仅由小写英文字母组成。- 所有
words[i]的长度之和不超过5 * 105。
地址
https://leetcode.cn/contest/weekly-contest-385/problems/count-prefix-and-suffix-pairs-ii/
题意
字符串哈希
思路
- 题目最难的在于如何判断出现相同的后缀与前缀,当然我们可以利用
kmp或者难懂的Z函数,但是最简单的方法还是字符串哈希算法,本题目使用哈希的话就非常常规的题目,对于每个字符串,我们统计其前缀与后缀相等的长度,并计算其哈希值,然后统计字符串中是否存在相同的哈希值的字符串的数目即可。 - 复杂度分析:
- 时间复杂度:$O(mn)$,其中 $m,n$ 分别表示数组的长度与字符串的平均长度。
- 空间复杂度:$O(m)$, $m$ 表示数组的长度。
代码
class Solution: |
欢迎关注和打赏,感谢支持!
扫描二维码,分享此文章