CMU 15-445/645 Lec5
05 Storage Models & Compression
DATA B A S E W O R K LOA D S
OLTP: On-Line Transaction Processing, 主要用来快速读取与更新数据,OLTP最重要的是事务。对OLTP最重要的是要能够快速的读取与更新数据,但是查询功能较弱,典型的特征是写的频率远大于读的频率。OLAP: On-Line Analytical Processing, 主要用来完成大量复杂的查询,主要用来进行数据的分析。OLAP典型的特征时支持大批量且复杂的查询。OLAP典型的工作场景是从OLTP数据库的收集数据,并对收集的数据进行查询与分析。HTAP:Hybrid Transaction + Analytical Processing, 同时具有OLTP与OLAP的功能特征,同时既能很好的支持读写与更新数据,只能支持超大规模的复杂查询。
Storage Models
典型的为 N-Ary Storage Model (NSM) 与 Decomposition Storage Model (DSM);
NSM: 也可成为行存储,数据库中表项中的每一行记录在page中连续存储,这种存储方式非常适合大量插入和更新,以及事务处理的OLTP类型数据库,因为只需要连续读取一次硬盘即可将某行的记录全部数据取出。
- 优点:插入、删除、更新速度很快,因为只需要读取一次
page中连续的存储区域即可,查询时方便查找整条记录,因为可以一次性读取整条记录; - 缺点:对于超大量的读取数据表中部分列数据非常低效,因为按照这样的存储方式需要将这个表中所有的记录全部读一遍。
- 优点:插入、删除、更新速度很快,因为只需要读取一次
DSM:分解存储模型,也可以称为列存储模型,表项中每一列做为一个整体单独在page中连续存储。适合大规模的读取与复杂查询场景,这种存储方式非常适合OLAP类型数据库。
- 优点:可以有效的降低
i/o的资源浪费,因为按照列存储,DBMS只需要读取指定查询的列即可,对于不需要的数据可以不用去page中读取;更加便于复杂查询的优化执行与数据的压缩; - 缺点:由于每一列可能存放在不同的存储区域中中,对于单点查询、更新、删除、插入效率不如行存储模型,由于每一列都存放在不同的
page中,更新或者删除一条记录需要同时更新多个不同的存储区域,实际效率较低
DSM tuple id:Fixed-length Offsets: 表项中的每一列均含有固定长度,每一列的offset在即为该项在表中的id编号,同一行中的不同列的数据在存储时具有相同的offset,查找某一行的记录时只需要在每一列中通过指定offset即可找到该行的数据,要求表项中每一列都必须具备相同的长度;Embedded Tuple Ids: 表项中的每一列均额外增加一个变量来存储其在表中的id编号,每次查询给定的行时,直接通过查询该列中绑定的id即可,由于每一列都需要存储id,这种存储方式的缺点是会带来额外的存储开销。

- 常见的数据库采用
dsm存储模型,绝大部分数据库均使用了列存储

- 优点:可以有效的降低
Database Compression
数据压缩技术广泛应用在基于硬盘存储的 dbms 系统,由于 disk i/o 很容易成为 dbms 的性能瓶颈,通过数据压缩技术可以有效降低 disk i/o 吞吐量从而提高性能,特别是在大规模的只读统计与分析的场景,在进行压缩与解压缩之前,通过压缩技术dbms 可以提前从硬盘预读取更多的数据。基于内存型的数据在查询时,不需要从硬盘读取数据,但是通过压缩技术可以降低内存的使用率,因此它们需要更多的考虑压缩率与性能之间的平衡,毕竟更高的压缩率在压缩与解压缩时需要耗费更多的 CPU cycle会降低性能。
压缩技术需要考虑的数据相关性,如果列中所有的数据均为随机码也就没有压缩的必要,但是真实的世界中数据集的分布总是存在一定的规律:
- 数据集呈现出高度的偏态分布,大部分数据可能集中某个区间,而不是随机的正态分布,例如
Zipfian distribution; - 数据集呈现出高度的相关性,比如城市的邮政编码,日期等数据;
基于以上对真实世界规律的观察,我们希望数据压缩尽可能的遵循以下原则:
- 产生固定长度的值:这是由于
dbms在存储时数据元素固定长度存储,可以使用偏移量来读取源数据,效率高; - 允许在查询结果返回后再进行解压,便于提高性能,而不需要每次查询前都需要进行数据解压反而带来性能下降;
- 必须是无损压缩:对于
dbms来说,数据信息在压缩过程中丢失不可接受的,因此在压缩时必须保证信息不会丢失;
Compression Granularity
在进行压缩前我们需要确定采用什么样的压缩方式,具体到哪一层级进行压缩,一般常见的有以下层级压缩:
Block Level: 在同一个表中对部分数据块进行压缩,比如可以对同一个表中连续几行进行压缩;Tuple Level: 对整个元组进行压缩,仅限于nsm存储模式Attribute Level: 对元组中的某一列属性进行压缩,可以压缩同一个元素中的多列属性。Columnar Level:为多元组的一列或者多列进行压缩;
Naive Compression
朴素压缩算法,常见的有 gzip, LZO, LZ4, Snappy, Brotli, Oracle OZIP, Zstd等压缩算法;
- 比如
mysql可以通过压缩技术将page压缩为大小为 $2^x$kb的数据块,便于缓存进行预读取,读取时将需要的page读取到内存中再进行解压缩; - 朴素的压缩算法虽然非常高效,但是使用场景有限,且没有关注数据内部的关联性;
Columnar Compression
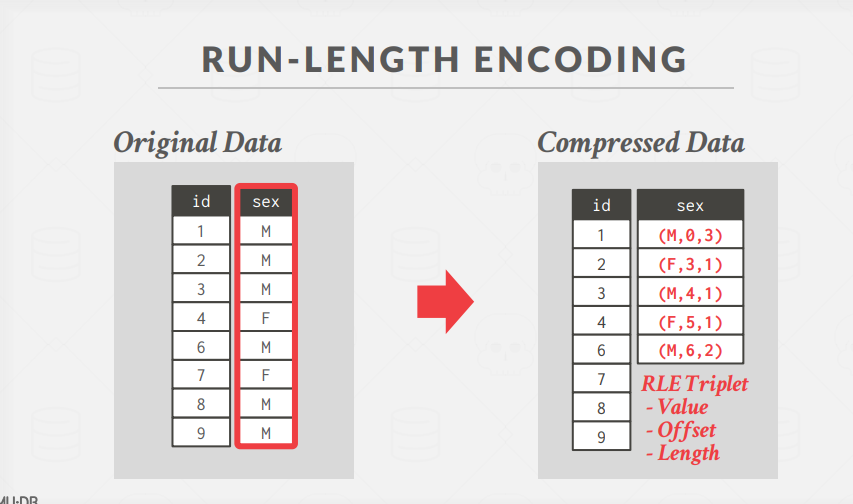
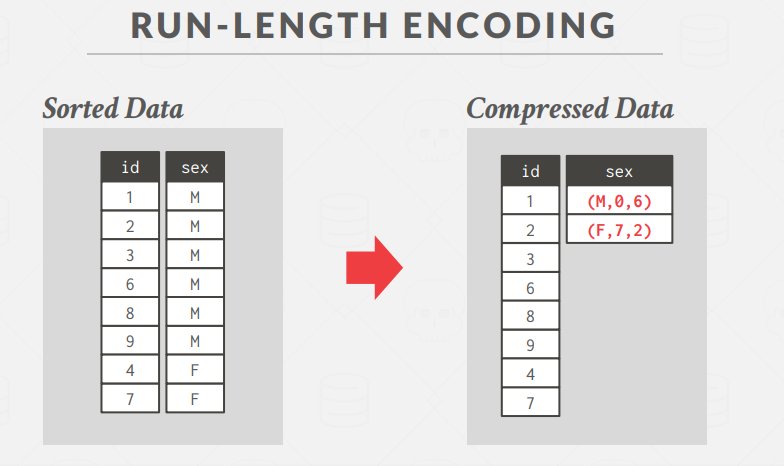
Run-length Encoding: 将单列中相同值的运行压缩为三元组,需要按照列的属性值进行排序,将相同的属性的值尽可能连续存放提高压缩率- 属性的值
- 列段的起始位置
- 列段的长度
Bit-Packing Encoding: 当属性的值始终小于该值声明的最大大小时,将它们存储为较小的数据类型。
Mostly Encoding:Bit-Packing Encodin的变体,使用特殊标记来指示值何时超过最大大小,然后用额外的表存储这些特殊值。
存储它们的查找表。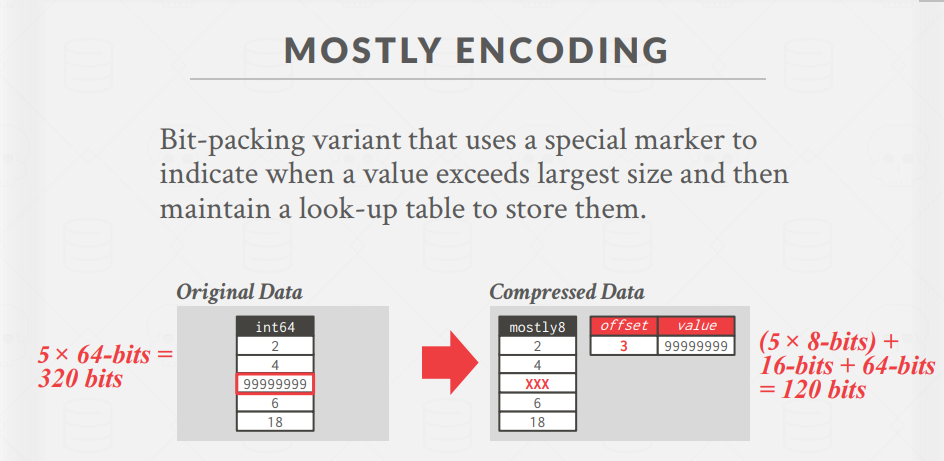
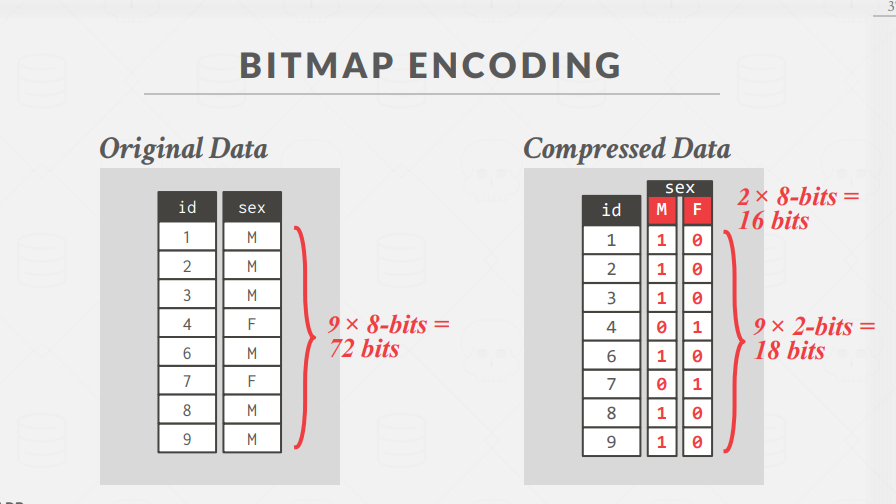
Bitmap Encoding: 位图,当列中属性值种类较少时,我们可以利用位图来标记每种属性即可,实际存放属性标记位图即可,但仅仅适用于属性值种类较少的情况。
Delta Encoding: 记录数值之间的差异即可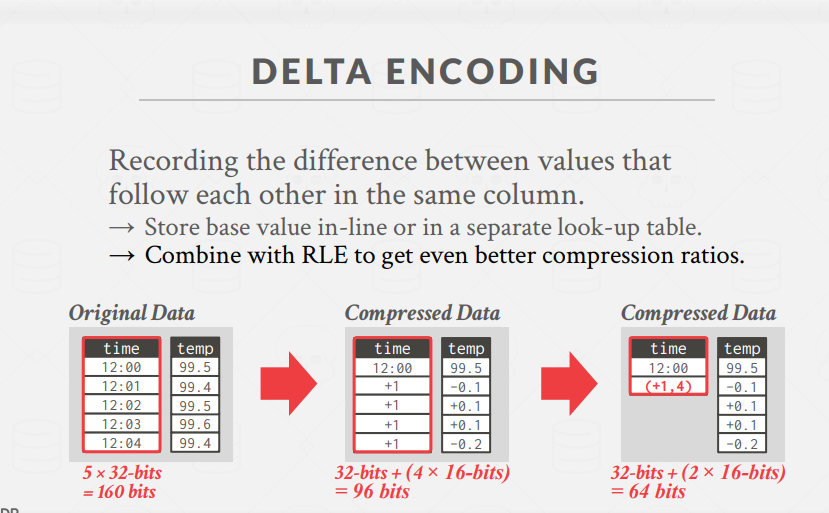
Incremental Encoding: 记录公共前缀或后缀及其长度,适用于排序数据
Dictionary Encoding:基于字典的压缩编码,最常见的数据库压缩方法。用较小的代码替属性中的原始值,dbms中只存储这些代码和一个数据结构(即字典,可以通过将这些代码映射到它们的原始值。通过字典查找来快速实现Encoding and Decoding,另外该编码需要支持范围查找与排序,即按照字典序编码后的排序结果要与编码前的排序结果保持一致,这样允许在查找时直接在编码后的结果上进行查找即可。
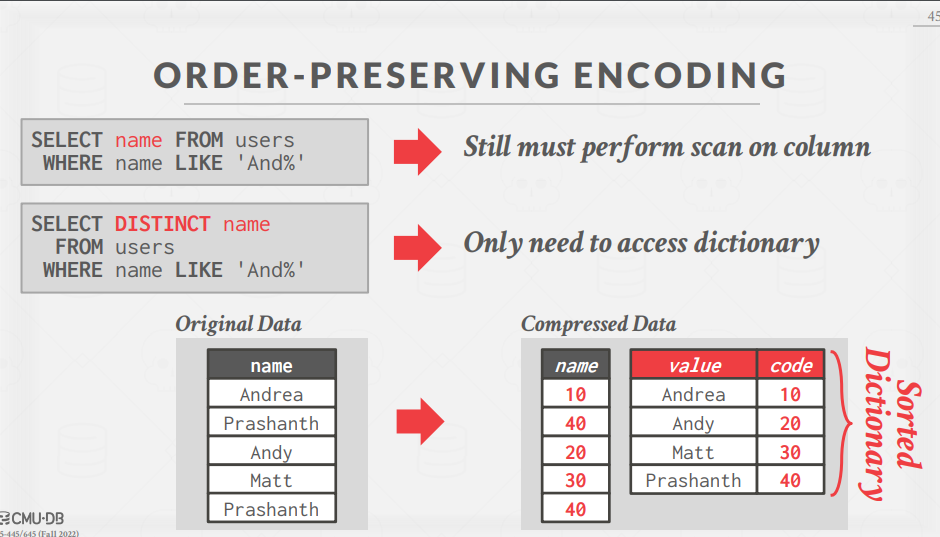
本章通过讲述了数据的存储结构基本信息,了解了数据中常见的数据类型等,需要通过下一章节详细了解数据库的存储结构。
总结
OLTP: 行存储OLAP: 列存储DBMS一般都会混合多种压缩方法,基于字典压缩编码是应用最广的一种压缩方法。
扫描二维码,分享此文章