MIT 6.S081 lab11 network
这个 lab我比较喜欢,因为本身从事过几年的网络设备研发工作,工作内容整体上来看倒不是非常复杂的。最感兴趣的倒是对网卡收包和发包部分的处理程序,因为本身对 dpdk 比较感兴趣的原因。这个 lab 其实涉及到一些网卡驱动的工作,代码内容看起来很大,倒是整个 lab 需要写的代码确实不需要太多,废话不多说,先总结一下该课程的课程内容,再针对性的对网卡的处理流程做一下回顾。
对于操作系统来说网卡也只是普通的外设,通过网络可以把不同的计算机连接起来,组成一个局域网。前面的几个章节讲了下网络协议,比较简单。常见的几个网络协议,
IP,arp,udp,tcp等都做了简要的回顾。网络协议栈:操作系统内部含有一个网络协议栈,通过
NIC driver从网卡中收包,然后进行处理。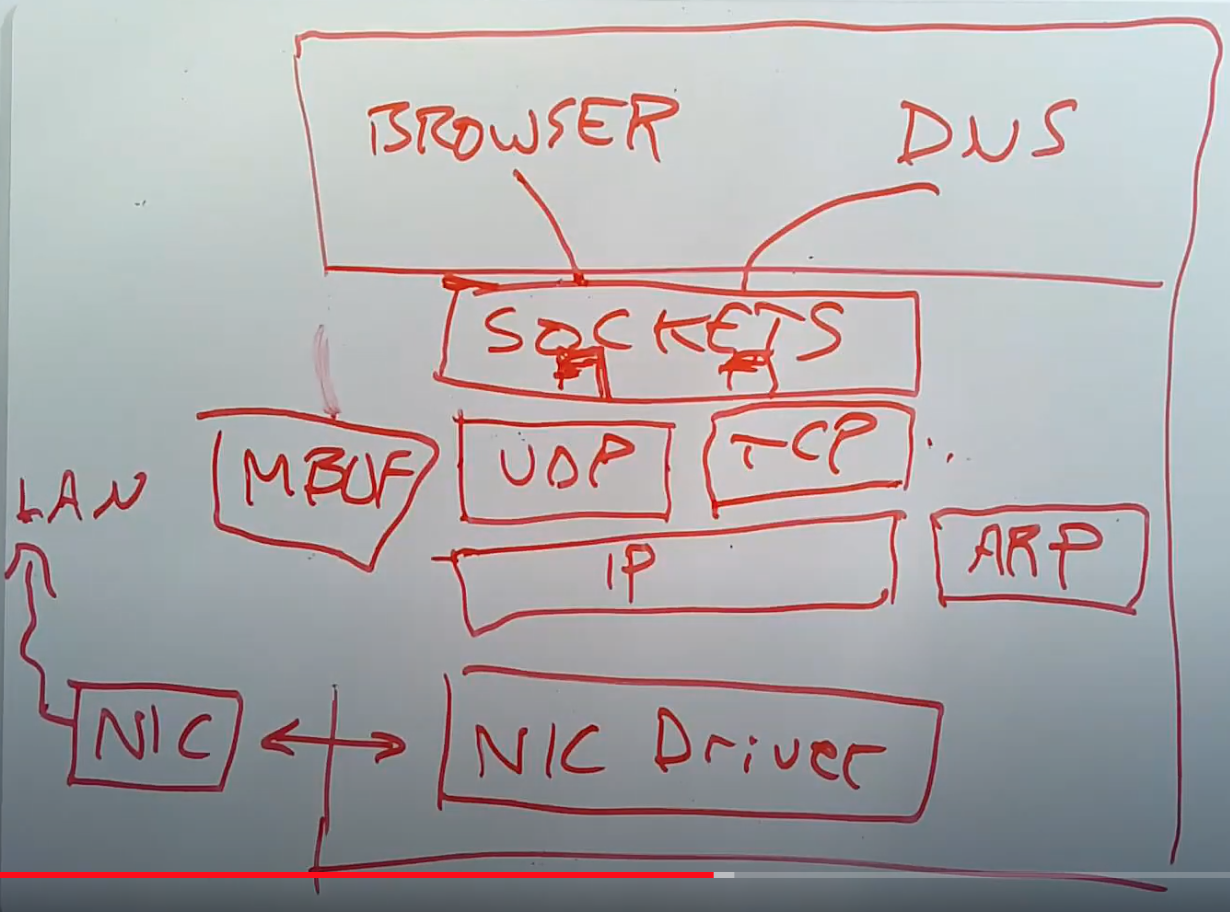
当一个packet从网络送达时,网卡会从网络中将packet接收住并传递给网卡驱动。网卡驱动会将packet向网络协议栈上层推送。在IP层,软件会检查并校验IP header,将其剥离,再把剩下的数据向上推送给UDP。UDP也会检查并校验UDP header,将其剥离,再把剩下的数据加入到socket layer中相应文件描述符对应的队列中。所以一个packet在被收到之后,会自底向上逐层解析并剥离header。当应用程序发送一个packet,会自顶向下逐层添加header,直到最底层packet再被传递给硬件网卡用来在网络中传输。所以内核中的网络软件通常都是被嵌套的协议所驱动。网卡在处理报文时有个重要的缓冲区叫做
packet buffer,实际的网络包处理都在ring buffer中进行处理。所以当收到了一个packet之后,它会被拷贝到一个ring buffer中,这个ring buffer会在网络协议栈中传递。通常整个网络协议栈都会使用buffer分配器,buffer结构。网卡的收包的处理流程:当网卡收到了一个
packet,它会生成一个中断。系统内核中处理中断的程序会被触发,并从网卡中获取packet。因为我们不想现在就处理这个packet,中断处理程序通常会将packet挂在一个队列中并返回,packet稍后再由别的程序处理。所以中断处理程序这里只做了非常少的工作,也就是将packet从网卡中读出来,然后放置到队列中。而在计算机的RAM中,会有GB级别的内存,所以计算机的内存要大得多。如果有大量的packet发送到网卡,网卡可能会没有足够的内存来存储packet,所以我们需要尽快将packet拷贝到计算机的内存中。内核中独立的线程来专门处理
packet,当该线程处理时如果发现该packet是某个socket需要等待读取的报文,则将该packet放置到该socket队列的队列中,等待应用程序读取;如果该内核作为路由器,则将报文进行处理后,放置到专门的网卡发送队列即可。
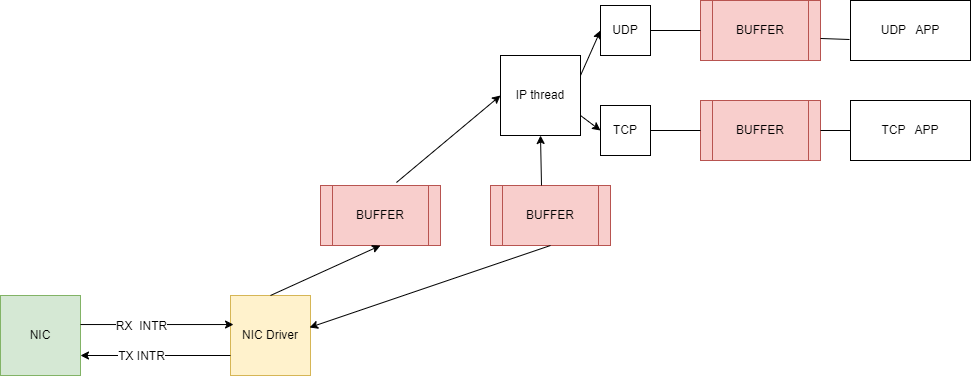
当
packet到达时,网卡会将packet存在自己的缓存中,并向主机发送中断,所以网卡内部会有一个队列。而主机的驱动包含了一个循环,它会与网卡交互,并询问当前是否缓存了packet。如果是的话,主机的循环会逐字节的拷贝packet到主机的内存中,再将内存中的packet加到一个队列中。在接受和发送报文时,网卡通过DMA控制内存的读取权限,直接从内存中写入和读取网络报文的内容。
通过中断的方式处理报文时,会发现存在一定的缺陷,由于
CPU频繁的陷入中断处理程序,从而导致CPU的报文处理效率不高,不断的陷入中断导致宝贵的CPU资源被浪费。可以发现到达一定的处理瓶颈后报文处理速度会下降,过多的CPU资源被浪费在处理中断上。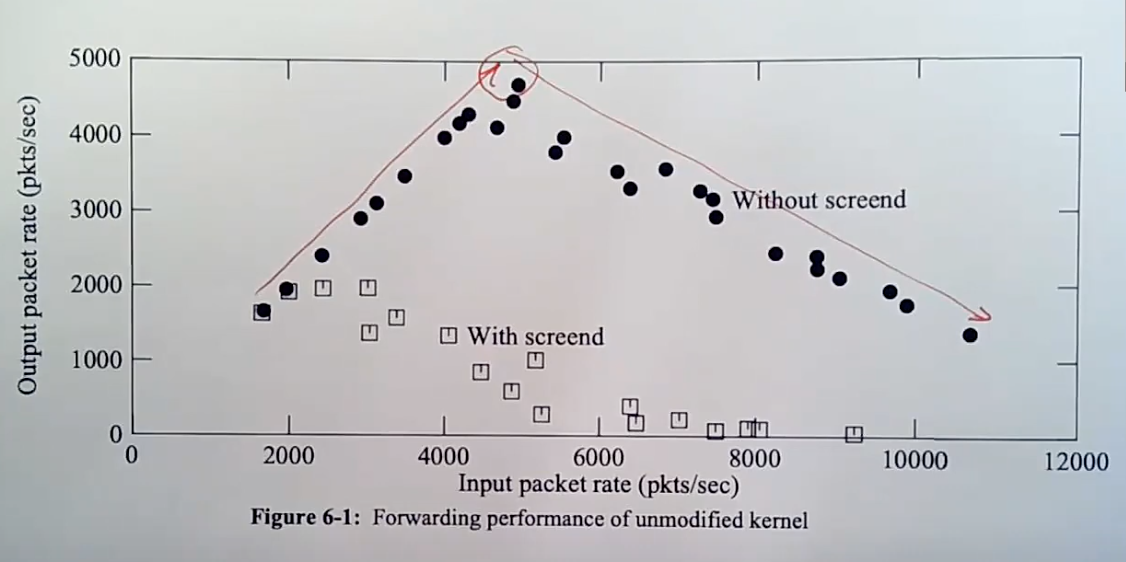
将网卡的处理模式从中断改为轮询模式。将中断模式(Interrupt Scheme)转变成了轮询模式(Polling Scheme)。在高负载的情况下,中断会被关闭,并且
CPU会一直运行这里的循环中,不断读取packet并处理packet。还是存在处理packet的线程和中断处理程序。当网卡第一次触发中断时,会导致中断处理函数的运行。但是中断处理函数并不会从网卡拷贝packet,相应的,它会唤醒处理packet的线程,并且关闭网卡的中断,这样接下来就收不到任何中断了。处理packet的线程会有一个循环,在循环中它会检查并从网卡拉取几个packet,论文中我记得是最多拉取5个packet,之后再处理这些packet。所以现在处理packet的线程是从网卡读取packet,而不是从中断处理程序读取。如果网卡中没有等待处理的packet,那么处理线程会重新打开网卡中断,并进入sleep状态。因为最后打开了中断,当下一个packet到达时,中断处理程序会唤醒处理packet线程,线程会从sleep状态苏醒并继续处理packet。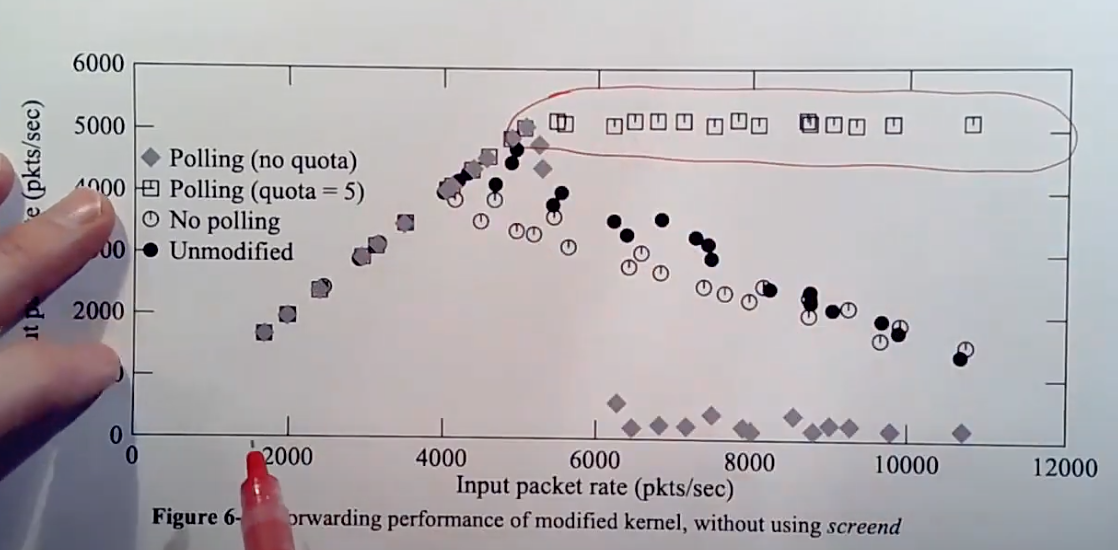
e1000的网卡驱动程序:
本文中也详细的描述了E1000网卡的驱动程序以及相应的网卡手册,参考给定的手册即可,其实比较简单。我们可以看到整个网卡的架构图如下: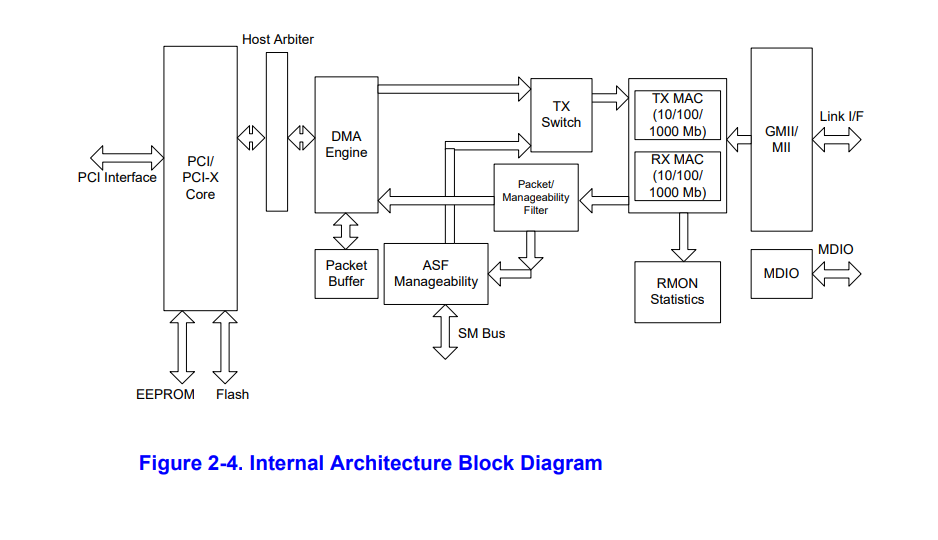
DMA工作原理:dma用来处理网卡收发报文时,网卡芯片上的内存与主机内存之间的数据交换,主要是报文数据与描述符。- 在接受方向上,
DMA存储在网卡上的FIFO缓存中的数据存到主机上的接受队列中,主要是数据报文的存储地址与描述符,同时也将以上内容写入到主机的内存中。 - 在发送方向上,
DMA将主机内存中数据拷贝到芯片的缓存去中,同时也将发送描述符写回到主机的内存中。 buffer queue就是网卡内部的缓冲队列,发送和接受都有,分别是TX和RX。DMA机制作用如下:在接收时,DMA引擎将队列中的数据拷贝到host内存,然后中断通知CPU。DMA机制是靠网卡设备的DMA Engine实现的,操作系统只起到配合的作用,例如在内存中划分一块DMA缓冲区用于读写。
- 在接受方向上,
initial:网卡初始化时,需要设置网卡的工作模式,并同时设置好网卡的接收描述符的ring buffer与缓存mbuffer,并设置好网卡的发送描述符的ring buffer与缓存mbuffer,同时设置好初始的FIFO队列,当设置好初始队列时head与tail。packet receive:网卡驱动每次收到报文时,对在队列的tail处添加报文的描述符,并同时将tail加1. 网卡硬件每次接收报文时,会直接将报文写head处,同时将head增加。当head等于tail时则认为队列为空, 当满足(head + 1) % size = tail时,此时队列已满,则会直接将报文进行丢弃。初始化时head = 0,tail = size - 1。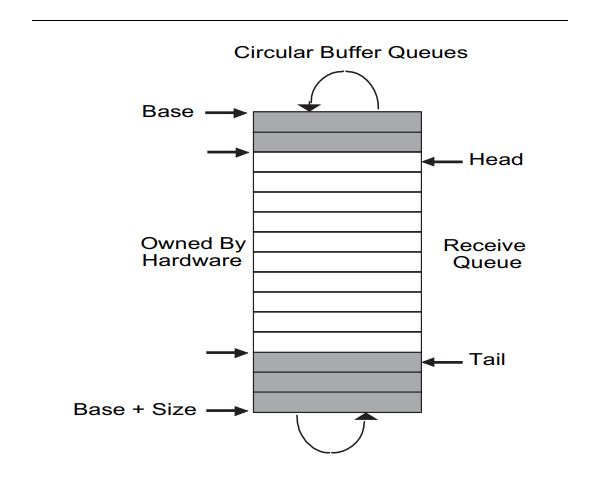
packet transmit:网卡驱动发送报文时,对在队列的tail处添加报文的描述符,并同时将tail加1. 网卡硬件每次接收报文时,会直接直接从head处读取描述符并写入网卡发送队列,同时将head增加。当head等于tail时则认为队列为空, 当满足(head + 1) % size = tail时,此时队列已满。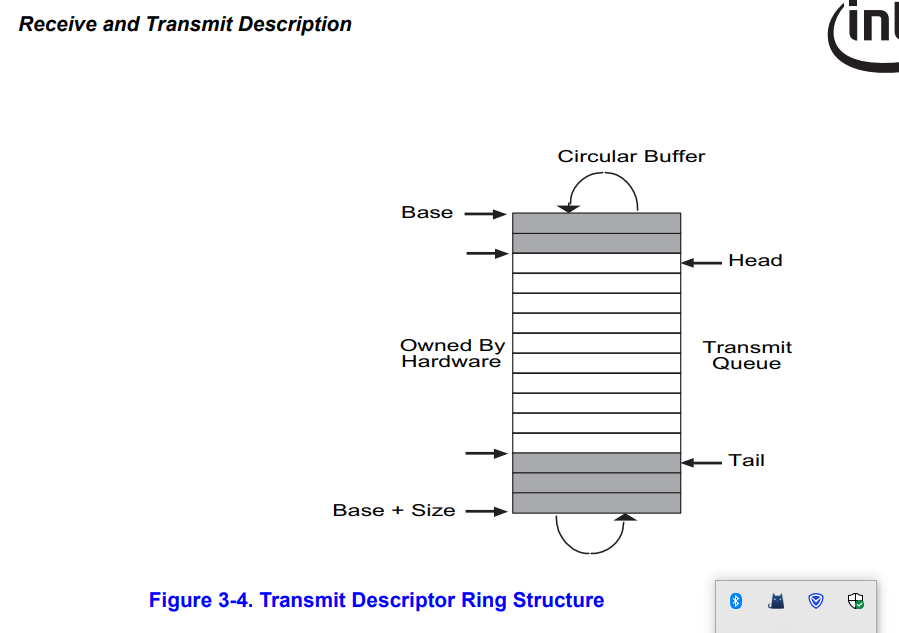
lab11 network
本节给的 lab 内容看似很复杂,结果实际却写不了几行代码,看着网卡操作手册和 hint 基本上就搞定了,唯一需要注意的是由于每次只能有一个线程使用网卡发送报文,此时我们需要对网卡的缓冲区加锁。在而收取报文时,由于只有一个中断程序来读取报文,所以不需要特别的加锁。当然在实际情况中可能不一样,网卡接受报文和发送报文时可能会有多个队列,实际可能需要针对不同的队列进行加锁。可能会有多个应用程序处理多个队列。
题目
Your job is to complete e1000_transmit() and e1000_recv(), both in kernel/e1000.c, so that the driver can transmit and receive packets. You are done when make grade says your solution passes all the tests. |
思考
network中需要实现网卡的报文接收int e1000_transmit(struct mbuf *m)与报文发送处理static void e1000_recv(void),我们可能需要先阅读一下相关的手册,了解一下基本的关于Descriptor的定义,这部分就非常简单了,查看datasheet文档即可。题目还给出了e1000_init函数的实现,就可以知道关于其初始化的基本流程了。发送初始化代码:
// Reset the device 关闭终端,并对网卡复位
regs[E1000_IMS] = 0; // disable interrupts
regs[E1000_CTL] |= E1000_CTL_RST;
regs[E1000_IMS] = 0; // redisable interrupts
// [E1000 14.5] Transmit initialization
memset(tx_ring, 0, sizeof(tx_ring));
for (i = 0; i < TX_RING_SIZE; i++) {
tx_ring[i].status = E1000_TXD_STAT_DD;
tx_mbufs[i] = 0;
} // 设置每个 ring buffer 的初始化状态
// 设置 ring buffer 的地址
regs[E1000_TDBAL] = (uint64) tx_ring;
if(sizeof(tx_ring) % 128 != 0)
panic("e1000");
// 设置 ring 的长度 与 队首与队尾的 offset
regs[E1000_TDLEN] = sizeof(tx_ring);
regs[E1000_TDH] = regs[E1000_TDT] = 0;
// [E1000 14.4] Receive initialization
// 初始化接收队列
memset(rx_ring, 0, sizeof(rx_ring));
// 对每个 mbuffer 进行初始化
for (i = 0; i < RX_RING_SIZE; i++) {
rx_mbufs[i] = mbufalloc(0);
if (!rx_mbufs[i])
panic("e1000");
rx_ring[i].addr = (uint64) rx_mbufs[i]->head;
}
// 设置队列的首地址
regs[E1000_RDBAL] = (uint64) rx_ring;
if(sizeof(rx_ring) % 128 != 0)
panic("e1000");
// 初始化 head tail.
regs[E1000_RDH] = 0;
regs[E1000_RDT] = RX_RING_SIZE - 1;
regs[E1000_RDLEN] = sizeof(rx_ring);
代码
int e1000_transmit(struct mbuf *m)将m中存储的网络报文发送到网卡中。代码实现非常简单,我们基本上参考hint就可以完成。Some hints for implementing e1000_transmit:
First ask the E1000 for the TX ring index at which it's expecting the next packet, by reading the E1000_TDT control register.
Then check if the the ring is overflowing. If E1000_TXD_STAT_DD is not set in the descriptor indexed by E1000_TDT, the E1000 hasn't finished the corresponding previous transmission request, so return an error.
Otherwise, use mbuffree() to free the last mbuf that was transmitted from that descriptor (if there was one).
Then fill in the descriptor. m->head points to the packet's content in memory, and m->len is the packet length. Set the necessary cmd flags (look at Section 3.3 in the E1000 manual) and stash away a pointer to the mbuf for later freeing.
Finally, update the ring position by adding one to E1000_TDT modulo TX_RING_SIZE.
If e1000_transmit() added the mbuf successfully to the ring, return 0. On failure (e.g., there is no descriptor available to transmit the mbuf), return -1 so that the caller knows to free the mbuf.
- 首先我们发送报文时需要加锁,然后从
regs[E1000_TDT]中读取队列的尾部指向的mbuf,并读取上一个index对应的报文是否已经完成发送,此时只需要读取status即可,并将该mbuffer释放,接着在该ring buffer处填充发送的描述符的相关信息,比如报文数据的存放地址,长度,以及CMD内容,并记录下该buffer,网卡在进行dma操作时会自动读该描述符相关内容并将报文数据拷贝到网卡上,从而完成报文发送。接着将tail进行自增,为下一个slot作为填充的位置。int
e1000_transmit(struct mbuf *m)
{
//
// Your code here.
//
// the mbuf contains an ethernet frame; program it into
// the TX descriptor ring so that the e1000 sends it. Stash
// a pointer so that it can be freed after sending.
//
acquire(&e1000_lock);
uint32 r_index = regs[E1000_TDT];
/* check the ring is overflow */
if ((tx_ring[r_index].status & E1000_TXD_STAT_DD) == 0) {
release(&e1000_lock);
return -1;
}
if (tx_mbufs[r_index]) {
mbuffree(tx_mbufs[r_index]);
}
/* fill the tx desciptor */
tx_ring[r_index].addr = (uint64)m->head;
tx_ring[r_index].length = (uint16)m->len;
tx_ring[r_index].cmd = E1000_TXD_CMD_RS | E1000_TXD_CMD_EOP;
tx_mbufs[r_index] = m;
regs[E1000_TDT] = (regs[E1000_TDT] + 1) % TX_RING_SIZE;
release(&e1000_lock);
return 0;
}
static void e1000_recv(void)完成报文的收取,根据题意可以知道当发生中断时,driver会从网卡的缓冲区读取所有可以读取的报文,并将其读到内存中。首先我们找到下一个index,如果下一个buffer的状态为未读则读取报文,否则则停止。直接调用net_rx从缓冲区中读取报文,从而完成了协议栈收包并处理,同时为当前的slot申请新的内存,并完成填充,并将tail进行递增。当然仅仅参考hint不用看手册就可以完成。当然网卡处理报文本身就比较复杂。static void
e1000_recv(void)
{
//
// Your code here.
//
// Check for packets that have arrived from the e1000
// Create and deliver an mbuf for each packet (using net_rx()).
//
while (1) {
uint32 r_index = (regs[E1000_RDT] + 1) % RX_RING_SIZE;
if ((rx_ring[r_index].status & E1000_RXD_STAT_DD) == 0) {
return;
}
rx_mbufs[r_index]->len = (uint32)rx_ring[r_index].length;
if (rx_mbufs[r_index]) {
net_rx(rx_mbufs[r_index]);
}
rx_mbufs[r_index] = mbufalloc(0);
rx_ring[r_index].addr = (uint64)rx_mbufs[r_index]->head;
rx_ring[r_index].status = 0;
regs[E1000_RDT] = r_index;
}
}
总结
总的来说这个 lab 还是非常有挑战性的,是个好的 lab,但是 lab 本身的代码倒不是很难,我觉得后面还是有机会仔细做一下 mit6.828 的 lab。我以为完成驱动代码需要非常多的技巧和文档需要阅读,结果代码量实在太少了。
欢迎关注和打赏,感谢支持!
- 关注我的博客: http://whistle-wind.com/
- 关注我的知乎:https://www.zhihu.com/people/da-hua-niu
- 关注我的微信公众号: 公务程序猿

扫描二维码,分享此文章