MIT6.824 2021 lab1
终于在跌跌撞撞中完成了MIT lab1 map-reduce的lab,仔细对比了一下,2021年的lab要比之前的lab要复杂一些,以前的map-reduce lab基本上只是Coordinator对任务进行主动调度,2021的lab会涉及到Coordinator被动接受worker的任务请求,然后进行被动的调度,同时加入了防止任务意外中止的校验,使得系统更加完善和健壮。所有的测试结果如下所示: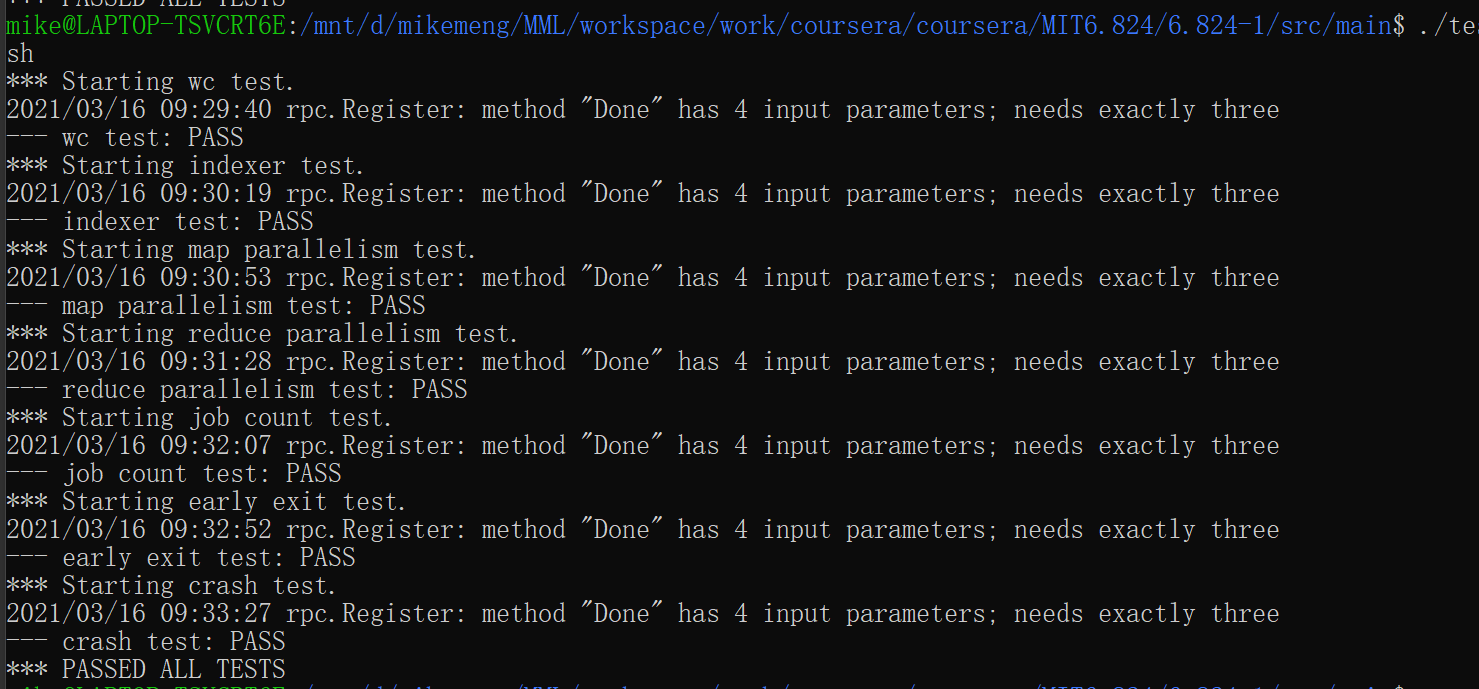
所有的代码都放在github上.
lab1
按照题目要求实现map-reduce系统,按照lab的要求实现调度器Coordinator和worker的基本功能,lab要求由woker主动向调度器发起任务请求,Coordinator按照当前的任务分配进度为每个worker分配map或者reduce任务,reduce任务必须在所有的map任务都完成后才能开始启动。其中的核心的难点并不是在于map和reduce的实现,难点在于如何做好worker和Coordinator之间的任务分配和调度。
Coordinator
Coordinator作为一个rpc server,处理所有从worker发送过来的rpc请求,当然在此也顺便学习了一下go的rpc框架,其实还是挺有意思的,非常方便的消息处理框架,首先我们需要设置好双方进行消息交互的rpc消息格式定义,目前定义如下:option请求定义:type OpType int
const (
TaskReq OpType = iota //请求分配任务
TaskMap //分配一个map类型的任务
TaskReduce //分配一个reduce类型的任务
TaskMapDone //完成一个map任务
TaskReduceDone //完成一个reduce任务
TaskDone //所有任务均已完成
TaskWait //等待当前任务完成
)rpc请求消息定义:type ReqArgs struct {
ReqId int64 // timestamp,作为本次请求分配的唯一标识。
ReqOp OpType // 消息类型
ReqTaskId int // 任务的ID编号
}rpc回应消息定义:type ReplyArgs struct {
RepId int64 // timestamp,作为某次请求的唯一标识。
RepOp OpType //消息类型
RepTaskId int //分配的任务ID
RepnMap int //map任务的总数
RepnReduce int //reduce任务的总数
RepContent string //map任务的文件名称
}Coordinator定义:type Coordinator struct {
// Your definitions here.
mapTasks chan int //待分配的map任务列表
reduceTasks chan int //待分配的reduce任务列表
nReduce int //reduce任务的数量
nMap int //map的任务数量
mapRuning []int64 //map任务状态
reduceRuning []int64 //reduce任务状态
tasks []string //待处理的文件名称
mapCnt int //当前未完成的map数量
reduceCnt int //当前未完成的reduce任务数量
taskDone bool //任务是否全部完成
lock *sync.Cond //互斥锁
}Coordinator接受到worker的请求后,根据请求的消息类型进行回应,如果当前的任务已经完成,则直接回应;如果请求的消息为任务请求,则查看是否存在待处理的map任务,如果存在则分发一个map类型的任务,如果map任务都已经下发但是还未全部完成,则通知worker进行等待;如果所有的map任务都已经下发且已经完成,则分配一个reduce类型的任务交给worker进行处理;如果接受的消息为worker通知任务完成,我们会校验该任务的标识,如果校验通过,我们将相应的任务状态设置为已经完成。- 最关键的一点处理,每当
Coordinator分配一个任务后,就会启动一个定时器任务,该定时器任务会在10s后检查该任务的状态是否已经完成,如果未完成,则将该任务再次进入到待分配列表中。 - 关键的临界区处理,这点我处理的不太好,为了图简单,直接在所有的存在竞争的数据访问处都用的互斥锁锁,其实也可以试试用
go的atmoic来定义某些关键数据类型,后面如果需要改进的话重点放在临界区访问的控制上。c.lock.L.Lock()
allDone := c.taskDone
c.lock.L.Unlock()
if allDone { //检验当前所有任务的状态,如果已经全部完成则直接返回
reply.RepId = args.ReqId
reply.RepOp = TaskDone
return nil
}
switch args.ReqOp{
case TaskReq: //任务请求
if len(c.mapTasks) > 0 { //如果存在待分配的map任务,则分配一个任务给当前的worker
reply.RepId = args.ReqId
reply.RepOp = TaskMap
reply.RepTaskId = <-c.mapTasks
reply.RepnMap = c.nMap
reply.RepContent = c.tasks[reply.RepTaskId]
reply.RepnReduce = c.nReduce
c.lock.L.Lock()
c.mapRuning[reply.RepTaskId] = args.ReqId //记录当前任务请求的标识
c.lock.L.Unlock()
go func(taskId int){ // 10s后检查该任务是否完成,如果未完成则将该任务再次进入待分配列表
time.Sleep(10*time.Second)
c.lock.L.Lock()
if c.mapRuning[taskId] != 1{
c.mapTasks<-taskId
}else{
c.mapCnt--
}
c.lock.L.Unlock()
}(reply.RepTaskId)
return nil
}else if len(c.mapTasks) == 0 {
c.lock.L.Lock()
mapCurr := c.mapCnt
reduceCurr := c.reduceCnt
c.lock.L.Unlock()
if mapCurr > 0 { // map任务全部分配,但是并未全部完成,此时需要通知worker进行等待
reply.RepId = args.ReqId
reply.RepOp = TaskWait
return nil
}else{
if len(c.reduceTasks) > 0 {// 如果存在待分配的reduce任务,则分配一个任务给当前的worker
reply.RepId = args.ReqId
reply.RepOp = TaskReduce
reply.RepTaskId = <-c.reduceTasks
reply.RepnMap = c.nMap
reply.RepnReduce = c.nReduce
c.lock.L.Lock()
c.reduceRuning[reply.RepTaskId] = args.ReqId
c.lock.L.Unlock()
go func(taskId int){
time.Sleep(10*time.Second) // 10s后检查该任务是否完成,如果未完成则将该任务再次进入待分配列表
c.lock.L.Lock()
if c.reduceRuning[taskId] != 1{
c.reduceTasks<-taskId
}else{
c.reduceCnt--
if c.reduceCnt == 0{
c.taskDone = true
}
}
c.lock.L.Unlock()
}(reply.RepTaskId)
}else{
if reduceCurr > 0 { // reduce任务全部分配,但是并未全部完成,此时需要通知worker进行等待
reply.RepId = args.ReqId
reply.RepOp = TaskWait
}
}
}
}
case TaskMapDone: // map任务完成,将该任务的状态置为完成
c.lock.L.Lock()
if c.mapRuning[args.ReqTaskId] == args.ReqId {
c.mapRuning[args.ReqTaskId] = 1
}
c.lock.L.Unlock()
case TaskReduceDone: // reduce任务完成,将该任务的状态置为完成
c.lock.L.Lock()
if c.reduceRuning[args.ReqTaskId] == args.ReqId{
c.reduceRuning[args.ReqTaskId] = 1
}
c.lock.L.Unlock()
default:
return nil
}
Worker
worker的处理就简单许多,主要是map处理和reduce处理,这个基本上可以参考lab给定的mrsequential代码即可,此时我们主要对map进行处理产生中间文件交给reduce处理即可。
map:从文件种读取所有的key-value数据,然后根据hash值写入不同的文件即可,当然这里的优化完全可以按照hash值进行排序,这样可以一次性将hash值相同的元素写入同一个文件,避免每次写入时写入不同的文件,从而可以加快处理速度。//
// main/mrworker.go calls this function.
//
// process a map task
func startMapTask(timestamp int64,reply * ReplyArgs,mapf func(string, string) []KeyValue) bool {
ifile, err := os.Open(reply.RepContent)
defer ifile.Close()
// read content from the file
content, err := ioutil.ReadAll(ifile)
if err != nil {
log.Fatalf("can not read %v", reply.RepContent)
}
intermediate := mapf(reply.RepContent, string(content)) // map任务处理
ofile := make([]*os.File,reply.RepnReduce)
for i := 0; i < reply.RepnReduce; i++ {
ofname := "mr-" + strconv.Itoa(reply.RepTaskId) + "-" + strconv.Itoa(i)
ofile[i], _ = os.Create(ofname)
defer ofile[i].Close()
}
for _,kv := range intermediate{ // 根据key的hash值写入相应的中间文件
reduceId := ihash(kv.Key)%reply.RepnReduce
enc := json.NewEncoder(ofile[reduceId])
err := enc.Encode(&kv)
if(err != nil){
log.Fatalf("can not read %v", ofile[reduceId])
}
}
//notice the server task finished
args := ReqArgs{} // 向Coordinator回应本次任务处理完成
args.ReqId = timestamp
args.ReqOp = TaskMapDone
args.ReqTaskId = reply.RepTaskId
nextreply := ReplyArgs{}
return call("Coordinator.Request", &args, &nextreply)
}reduce:从文件种读取所有的key hash值相同的数据,然后根据key进行排序,将相同的key的元素进行reduce处理,处理完成后结果写入到目标文件种,全部完成后通知Coordinator本次任务完成。/ process a reduce task
func startReduceTask(timestamp int64,reply * ReplyArgs,reducef func(string, []string) string) bool {
// we check every intermediate map task file
kva := []KeyValue{}
for i := 0; i < reply.RepnMap; i++ { //读取所有的中间文件
ifilename := "mr-" + strconv.Itoa(i) + "-" + strconv.Itoa(reply.RepTaskId)
ifile, err := os.Open(ifilename)
defer ifile.Close()
// open file error
if err != nil{
log.Fatalf("Open File Error.")
}
// read all intermediate data from the file
dec := json.NewDecoder(ifile)
for {
var kv KeyValue
if err := dec.Decode(&kv); err != nil {
break
}
kva = append(kva, kv)
}
}
//store intermediate data to the out file
sort.Sort(ByKey(kva)) //排序
// write to the target file
ofilename := "mr-out-" + strconv.Itoa(reply.RepTaskId)
//fmt.Println("out file %v",ofilename)
ofile,err := os.Create(ofilename)
if err != nil{
log.Fatalf("Creat Open File Error.")
}
defer ofile.Close()
i := 0
for i < len(kva) { //按照相同的key进行分配,并进行reduce处理
j := i + 1
for j < len(kva) && kva[j].Key == kva[i].Key {
j++
}
values := []string{}
for k := i; k < j; k++ {
values = append(values, kva[k].Value)
}
output := reducef(kva[i].Key, values)
// this is the correct format for each line of Reduce output.
fmt.Fprintf(ofile, "%v %v\n", kva[i].Key, output)
i = j
}
//notice the server task finished
args := ReqArgs{} // 向Coordinator回应本次任务处理完成
args.ReqId = timestamp
args.ReqOp = TaskReduceDone
args.ReqTaskId = reply.RepTaskId
nextreply := ReplyArgs{}
return call("Coordinator.Request", &args, &nextreply)
}
Map-Reduce
根据paper中的描述如下: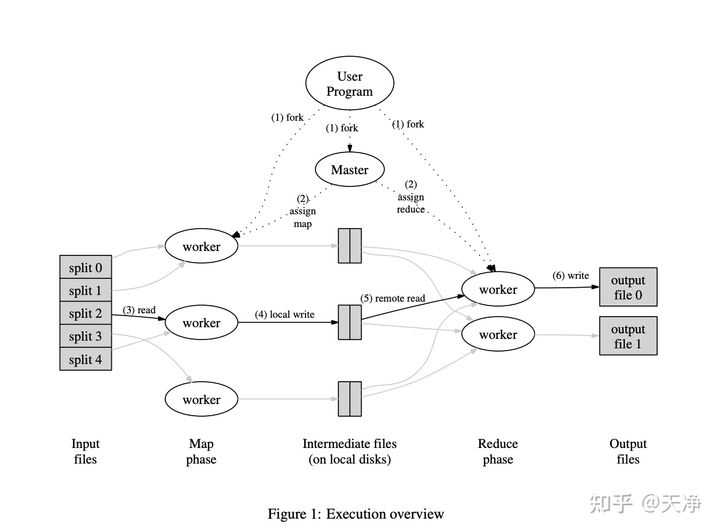
- 假设有
M个map操作,n个reduce操作, 那么master一共要安排M +N个worker任务 。 - 每个
map操作将生成n个文件,map过程一共产生m*n个文件. map操作完成后的数据是以文件的形式存储的.
实际处理过程:首先将 文档分成m份,每一份调用一个map函数操作并生成n个文件 。所有map操作完成后进行reduce操作,对于 每个reduce操作,从上一步生成 的m*n个文件中选取对应的m个文件 进行reduce操作,完成后将结果写入$n_{i}$ 中。 所有reduce操作完成后将n个临时文件合并成最终的output文件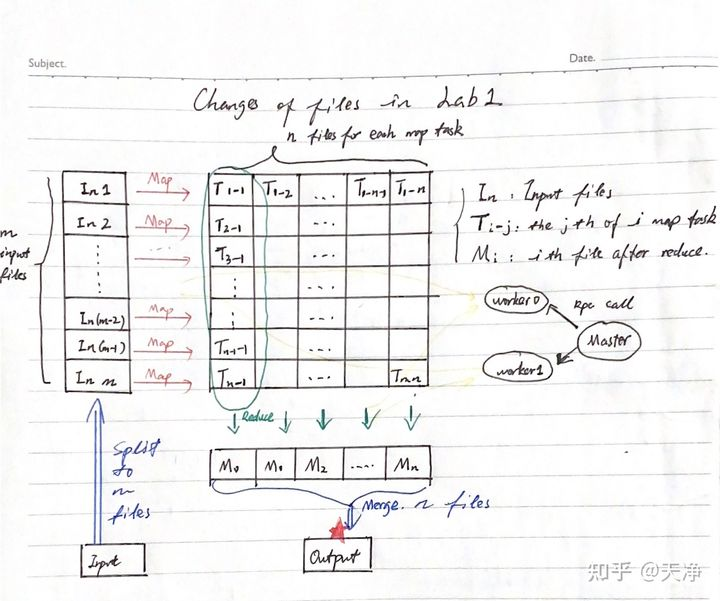
欢迎关注和打赏,感谢支持!
- 关注我的博客: http://mikemeng.org/
- 关注我的知乎:https://www.zhihu.com/people/da-hua-niu
- 关注我的微信公众号: 公务程序猿

扫描二维码,分享此文章