clickhouse学习记录(一)
最近因为工作原因,开始尝试学习clickhouse数据库, 将会逐渐将clickhouse的一些学习总结记录下来, 作为自己的学习历程.
clickhouse的简介
项目起源clickhouse是由俄罗斯的一家互联网公司 Yandex 开发的, Yandex 主要从事互联网分析,Yandex 使用 clickhouse 从事海量的互联网的流量分析,clickhouse 作为 Yandex 公司内部使用的项目, 后来走向开源. clickhouse 作为 OLAP 领域的流行, 主要得益于其出色的性能.
数据库领域有两个概念:
OLTP: on-line transaction processing翻译为联机事务处理,OLTP是主要从事事务处理, 包括数据库常见的增删改.OLTP主要用来记录某类业务事件的发生,如购买行为,当行为产生后,系统会记录是谁在何时何地做了何事,这样的一行(或多行)数据会以增删改的方式在数据库中进行数据的更新处理操作,要求实时性高、稳定性强、确保数据及时更新成功,像公司常见的业务系统如ERP,CRM,OA等系统都属于OLTP.OLAP: On-Line Analytical Processing翻译为联机分析处理,OLAP是主要侧重于数据分析和查询, 主要侧重的功能是数据库的查询.当数据积累到一定的程度,我们需要对过去发生的事情做一个总结分析时,就需要把过去一段时间内产生的数据拿出来进行统计分析,从中获取我们想要的信息,为公司做决策提供支持,这时候就是在做OLAP了。数据仓库: 因为
OLTP所产生的业务数据分散在不同的业务系统中,而OLAP往往需要将不同的业务数据集中到一起进行统一综合的分析,这时候就需要根据业务分析需求做对应的数据清洗后存储在数据仓库中,然后由数据仓库来统一提供OLAP分析。所以我们常说OLTP是数据库的应用,OLAP是数据仓库的应用。
详细可以参考知乎的回答
clickhouse的特性clickhouse 采用列式存储, 所有的数据都是以列为单位进行组织和存储的, clickhouse的最大的特色就是以性能著称, 官方的文档也给出了相关的性能对比.clickhouse的特性:
- 以列为存储, 同一列的数据格式统一, 方便使用数据压缩算法. 目前
clickhouse使用的LZ4压缩算法. 数据压缩可以带来两个好处, 数据存储的空间较小从而读写磁盘花费时间较短, 网络传输中也会较少缓存时间. ClickHouse允许在运行时创建表和数据库、加载数据和运行查询,而无需重新配置或重启服务。具有完成的数据库管理系统的功能.- 多核心并行处理, 充分利用
CPU的资源, 设计时针对具体的硬件进行充分优化, 从而提升性能. 看到字符串搜索中竟然用到了intel hyperscan, 这个是dpi设备里面常用的字符串搜索算法. 支持CPU的SIMD指令, 可以向量执行数据的处理和读取. - 支持多服务器分布式处理, 支持分布式查询, 可以进行负载均衡.
- 实时的数据更新, 为了使查询能够快速在主键中进行范围查找,数据总是以增量的方式有序的存储在
MergeTree中。因此,数据可以持续不断地高效的写入到表中,并且写入的过程中不会存在任何加锁的行为。 click house中的很多优化技巧都值得仔细学习和琢磨.
clickhouse的不足之处
clickhouse 主要用于数据分析, 也有许多缺点.
- 不支持事务
ACID。 - 缺少高频率,低延迟的修改或删除已存在数据的能力,以行进行更新数据的话性能较差.。
- 稀疏索引使得
ClickHouse不适合通过其键检索单行的点查询。
clickhouse的发展现状
click 以其出色的性能, 目前在很多很多BI领域得到应用, 还有许多广告流量,web分析, 电子商务等领域. 以下为常见的几个学习的资源库:
clickhouse文档: https://clickhouse.com/docs/zh/clickhouserepo: https://github.com/ClickHouse/ClickHouseclickhouse中文社区: http://www.clickhouse.com.cn/clickhouse官方:https://clickhouse.com/
clickhouse的安装部署
server安装:官方提供的guide有许多种安装方式, 强烈推荐使用apt-get或者yum这种标准安装包的形式来安装,会自动更新和下载各种库, 自己可以下载源码,然后编译到本地进行安装, 机器性能太差, 编译实践太长, 中间容易经历各种坑,新手强烈不推荐. 安装过程踩过的坑是, 直接下载官方提供的编译好的库和程序,windows自带的wsl安装后反正各种莫名奇妙的问题,各种莫名奇妙的abort退出, 也找不到问题原因所在, 反而远程的VPS安装一次就顺利.config文件说明: 默认的config文件会存放在/etc/clickhouse-server/config.xml目录下, 安装完成之后需要进行修改, 当然默认的clickhouse server只监听在本地127.0.0.1, 需要进行修改使得它可以接受所有外部的主机发起的tcp请求. 高级的配置文件参数定义可以参考官方的文档:配置文件.<!--允许所有的ipv6的请求-->
<listen_host>::</listen_host>
<!--允许所有的ipv4的请求-->
<listen_host>0.0.0.0</listen_host>server启动与测试: 直接执行clickhouse-server时, 会提示要求创建clickhouse:clickhouse账户, 建议直接使用脚本启动服务,root账户启动即可,需要修改配置文件,默认要求使用clickhouse的用户名.sudo service clickhouse-server start
查看进程:

查看端口:
vps firewall设置: 直接将centos的防火墙关掉, 由于是远程VPS需要设置端口号, 允许clickhouse服务通行: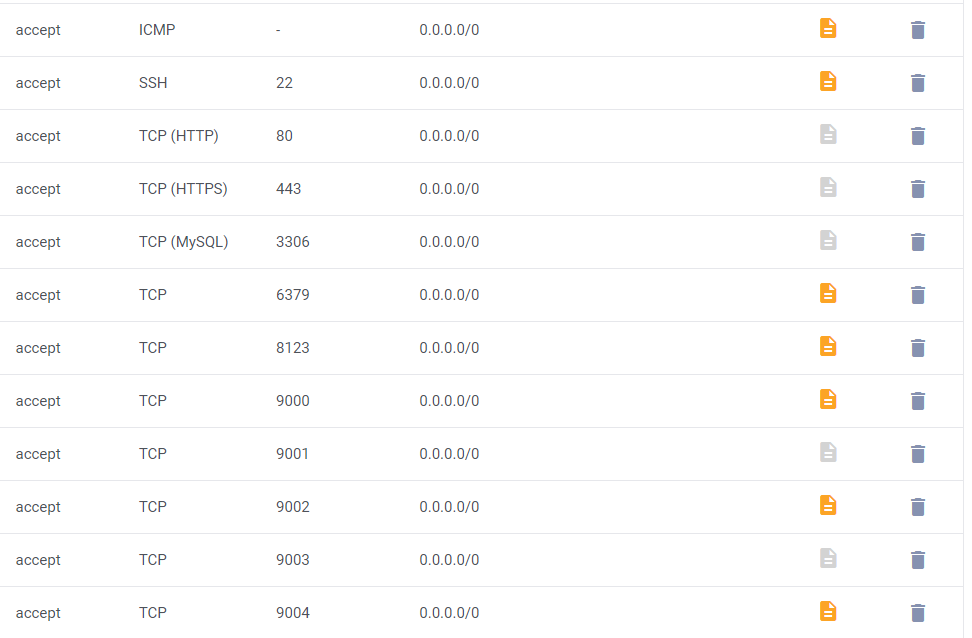
clickhouse的使用测试
我们可以通过clickhouse自带的clickhouse-client程序来本地或者远程访问clickhouse server, 尝试以下数据库的基本操作:
- 连接数据库
server:clickhouse-client默认就会连接本地的clickhouse的数据库server, 我们尝试连接远程的vps,clickhouse-client --host=x.x.x.x即可连接指定ip的数据库。clickhouse-client --query='xx'即可执行query中sql语句. - 创建数据库: 创建
test数据库,clickhouse-client --query='CREATE DATABASE IF NOT EXISTS test'. - 创建表项: 创建
numbers表项,clickhouse-client --query='CREATE TABLE IF NOT EXISTS test.numbers (id UInt64, name String) ENGINE = Memory'. - 插入表项: 插入
numbers行,clickhouse-client --query='INSERT INTO test.numbers VALUES (100, 'mengmingliang')'. - 删除表项: 删除
numbers行,clickhouse-client --query='INSERT INTO test.numbers VALUES (100, 'mengmingliang')'. - 查询表项: 查询基本的表,
clickhouse-client --query='SELECT id, name FROM test.numbers'; - 删除数据表项: 删除
numbers表,DROP TABLE test.numbers.
clickhouse client的连接接口测试
clickhouse提供了多种通用的接口用来连接和操作数据, 提供了http和tcp的两种访问接口形式,http的访问端口为8123, tcp的端口为9000, 我们可以在浏览器中输入http://localhost:8123就会打印出ok, 浏览器中输入http://localhost:8123/?query=SELECT%201就会返回查询结果. http的接口主要用于Java的开发,我们可以使用标准的jdbc来访问数据库, HTTP接口比原生接口受到更多的限制,但它具有更好的兼容性.tcp端口主要用于服务器间的通讯查询和管理,同时也支持数据库的查询,比http的接口会更加灵活使用, 官方目前只提供了标准的C++接口, 这种接口目前没有标准, 但是我能想到的是很容易对这些接口来进行扩展, 从而来对clickhouse增加新的功能和特性,这点确实不错, 为程序的灵活性做了更多的扩展.
- 通过
C++接口测试: 我们可以下载官方提供的标准的C++的接口CPP, 下载之后进行编译, 需要注意的是由于clickhouse是用C++17的标准编写的, 需要升级本地的gcc程序支持C++ 17.编译完成之后发现支持静态链接库, 手动写个简单makefile, 测试跑了一遍, 还算比较正常. 下一步需要走读和分析一下clinet的代码, 熟悉一下原理, 尝试一下后面是否有扩展的可能性, 示例代码放在github. - 通过
Python接口测试:python的接口不是官方团队提供是, 是由第三方提供的代码, 目前尝试了一下clickhouse-driver这个第三方的库, 很多功能都没有深入尝试, 后面有时间时需要进行深入的探索. - 通过
DBeaver接口测试: 下载尝试了一下通过可户端去连接clickhouse, 用Gui的客户端确实方便很多, 可以通过标准的jdbc接口去连接数据库, 需要下载clickhouse的驱动,我们可以很方便的访问数据库.可以直接执行标准的sql语句. 可以直接通过接口导入和导出数据, 确实比用纯粹的程序实现要方便许多.
clickhouse client的高级特性尝试
- 创建数据库:
CREATE DATABASE IF NOT EXISTS db_name [ENGINE = engine]Ordinary:默认引擎,在绝大多数情况下我们都会使用默认引擎,使用时无须刻意声明。在此数据库下可以使用任意类型的表引擎。Dictionary:字典引擎,此类数据库会自动为所有数据字典创建它们的数据表,关于数据字典的详细介绍会在第5章展开。Memory:内存引擎,用于存放临时数据。此类数据库下的数据表只会停留在内存中,不会涉及任何磁盘操作,当服务重启后数据会被清除。Lazy:日志引擎,此类数据库下只能使用Log系列的表引擎,关于Log表引擎的详细介绍会在第8章展开。MySQL:MySQL引擎,此类数据库下会自动拉取远端MySQL中的数据,并为它们创建MySQL表引擎的数据表
进一步打算
- 学习
SQL的高级语法基础知识以及数据库的高级一些理论知识,进行理论基础知识补充。
- 学习
clickhouse中文社区中找一些经典的入门资料进行学习,学习相关书籍clickhouse原理解析与应用实践。
- 熟悉和掌握实际业务中常用的
clickhouse的高级特性和功能,并掌握背后的相关原理。
- 熟悉和掌握实际业务中常用的
- 相关业务知识和语言技能的掌握,熟悉相关的
JAVA/C++关于操作数据库的接口api函数的使用。
- 相关业务知识和语言技能的掌握,熟悉相关的
欢迎关注和打赏,感谢支持!
- 关注我的博客: http://mike-box.github.io/
- 关注我的知乎:https://www.zhihu.com/people/da-hua-niu
- 关注我的微信公众号: 公务程序猿

扫描二维码,分享此文章