leetcode biweekly contest 90
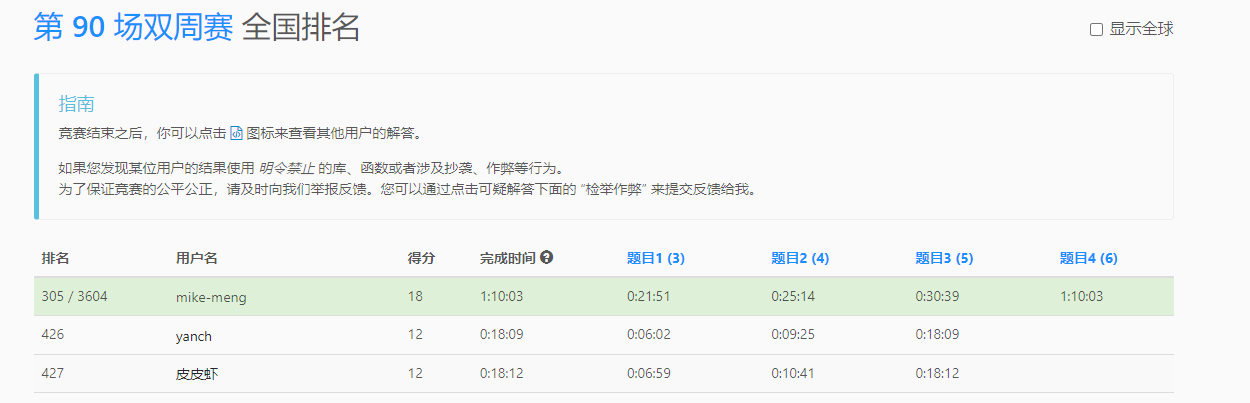
前三题都是水题,第四题想了半天没想出来简单的办法,直接单调栈加上线段树二分暴力,也没有想到更好的办法,除了菜没办法。
6225. 差值数组不同的字符串
题目
给你一个字符串数组 words ,每一个字符串长度都相同,令所有字符串的长度都为 n 。
每个字符串 words[i] 可以被转化为一个长度为 n - 1 的 差值整数数组 difference[i] ,其中对于 0 <= j <= n - 2 有 difference[i][j] = words[i][j+1] - words[i][j] 。注意两个字母的差值定义为它们在字母表中 位置 之差,也就是说 'a' 的位置是 0,'b' 的位置是 1 ,'z' 的位置是 25 。
比方说,字符串 "acb" 的差值整数数组是 [2 - 0, 1 - 2] = [2, -1] 。words 中所有字符串 除了一个字符串以外 ,其他字符串的差值整数数组都相同。你需要找到那个不同的字符串。
请你返回 words中 差值整数数组 不同的字符串。
示例 1:
输入:words = ["adc","wzy","abc"] |
示例 2:
输入:words = ["aaa","bob","ccc","ddd"] |
提示:
3 <= words.length <= 100n == words[i].length2 <= n <= 20words[i]只含有小写英文字母。
地址
https://leetcode.cn/contest/biweekly-contest-90/problems/odd-string-difference/
题意
直接模拟
思路
- 直接模拟了,没啥好说的,暴力循环然后找到出现次数最少的即可
- 复杂度分析:
- 时间复杂度:$O(n)$。
- 空间复杂度:$O(n)$。
代码
class Solution { |
6228. 距离字典两次编辑以内的单词
题目
给你两个字符串数组 queries 和 dictionary 。数组中所有单词都只包含小写英文字母,且长度都相同。
一次 编辑 中,你可以从 queries 中选择一个单词,将任意一个字母修改成任何其他字母。从 queries 中找到所有满足以下条件的字符串:不超过 两次编辑内,字符串与 dictionary 中某个字符串相同。
请你返回 queries 中的单词列表,这些单词距离 dictionary 中的单词 编辑次数 不超过 两次 。单词返回的顺序需要与 queries 中原本顺序相同。
示例 1:
输入:queries = ["word","note","ants","wood"], dictionary = ["wood","joke","moat"] |
示例 2:
输入:queries = ["yes"], dictionary = ["not"] |
提示:
1 <= queries.length, dictionary.length <= 100n == queries[i].length == dictionary[j].length1 <= n <= 100- 所有
queries[i]和dictionary[j]都只包含小写英文字母。
地址
https://leetcode.cn/contest/biweekly-contest-90/problems/words-within-two-edits-of-dictionary/
题意
遍历
思路
- 这个题目也是暴力循环即可,直接计算两个字符串的编辑距离即可,非常简单的题目了。
- 复杂度分析:
- 时间复杂度:时间复杂度为 $O(nm)$,其中 $n$ 表示给定的数组的长度,$m$ 表示字符串的长度。
- 空间复杂度:空间复杂度为 $O(1)$。
代码
class Solution { |
6226. 摧毁一系列目标
题目
给你一个下标从 0 开始的数组 nums ,它包含若干正整数,表示数轴上你需要摧毁的目标所在的位置。同时给你一个整数 space 。
你有一台机器可以摧毁目标。给机器 输入 nums[i] ,这台机器会摧毁所有位置在 nums[i] + c * space 的目标,其中 c 是任意非负整数。你想摧毁 nums 中 尽可能多 的目标。
请你返回在摧毁数目最多的前提下,nums[i] 的 最小值 。
示例 1:
输入:nums = [3,7,8,1,1,5], space = 2 |
示例 2:
输入:nums = [1,3,5,2,4,6], space = 2 |
示例 3:
输入:nums = [6,2,5], space = 100 |
提示:
1 <= nums.length <= 1051 <= nums[i] <= 1091 <= space <= 109
地址
https://leetcode.cn/contest/biweekly-contest-90/problems/destroy-sequential-targets/
题意
数学问题
思路
- 通过分析可以知道如果 $x$ 与 $y$ 按照题目要求可以变换,则一定满足 $x \mod space = y \mod space$。此时我们对于每个 $nums[i]$ 只需要统计出 $nums[i] \mod space$ 的个数即可。
- 最后我们按照题目要做只需要找到 $nums[i] \mod space$ 的最大数目,且满足 $nums[i]$ 最小即可。
- 复杂度分析
- 时间复杂度:时间复杂度为 $O(n)$,$n$ 为数组的长度。
- 空间复杂度:时间复杂度为 $O(n)$。
代码
class Solution { |
6227. 下一个更大元素 IV
题目
给你一个下标从 0 开始的非负整数数组 nums 。对于 nums 中每一个整数,你必须找到对应元素的 第二大 整数。
如果 nums[j] 满足以下条件,那么我们称它为 nums[i] 的 第二大 整数:
j > inums[j] > nums[i]
恰好存在 一个k满足i < k < j且nums[k] > nums[i]。
如果不存在nums[j],那么第二大整数为-1。
比方说,数组 [1, 2, 4, 3] 中,1 的第二大整数是 4 ,2 的第二大整数是 3 ,3 和 4 的第二大整数是 -1 。
请你返回一个整数数组 answer ,其中 answer[i]是 nums[i] 的第二大整数。
示例 1:
输入:nums = [2,4,0,9,6] |
示例 2:
输入:nums = [3,3] |
提示:
1 <= nums.length <= 1050 <= nums[i] <= 109
地址
https://leetcode.cn/contest/biweekly-contest-90/problems/next-greater-element-iv/
题意
数学问题
思路
- 我们将本题拆分成两个子问题:
- 下一个更大的元素;
- 从 $i$ 开始找到第一个比 $x$ 大的数;
如果上面两个子问题都可以解决,那么本题就是一个常规题目了。
- 首先我们找到每个元素 $nums[i]$ 下一个更大元素的位置为 $j$,然后从 $j + 1$ 处开始查找第一个比 $nums[i]$ 大的元素,此时我们可以利用线段树上二分查找。
- 排序也非常简单的问题,排序也是非常好的思路来解决该问题,我们将所有的元素按照从大道小的顺序进行排序,同时对于相同的元素按照索引的小到大的顺序来进行排序,此时我们从大到小依次将元素的索引加入到有序集合中,保证每次加入 $nums[i]$ 时,集合中只保存大于 $nums[i]$ 的元素,每次我们查询有序集合中第一个大于 $i$ 的索引为 $j$ 即可,再往后移动一个元素即可。
- 复杂度分析:
- 时间复杂度:$O(n \log n)$,其中 $n$ 表示给定的数组的长度。
- 空间复杂度:$O(n)$,其中 $n$ 表示给定的数组的长度。
代码
class Solution { |
- 排序 + 二分查找
class Solution {
public:
vector<int> secondGreaterElement(vector<int>& nums) {
int n = nums.size();
vector<pair<int, int>> arr;
for (int i = 0; i < nums.size(); i++) {
arr.emplace_back(nums[i], i);
}
sort(arr.begin(), arr.end(), [](const pair<int, int> &a, const pair<int, int> &b) {
if (a.first == b.first) {
return a.second < b.second;
}
return a.first > b.first;
});
set<int> cnt;
vector<int> ans(n, -1);
for (auto [x, i] : arr) {
auto it = cnt.lower_bound(i);
if (it != cnt.end() && (++it) != cnt.end()) {
ans[i] = nums[*it];
}
cnt.emplace(i);
}
return ans;
}
};
欢迎关注和打赏,感谢支持!
- 关注我的博客: http://mikemeng.org/
- 关注我的知乎:https://www.zhihu.com/people/da-hua-niu
- 关注我的微信公众号: 公务程序猿

扫描二维码,分享此文章